
The Data Transfer Project was launched in 2018 to create an open-source, service-to-service data portability platform so that all individuals across the web could easily move their data between online service providers whenever they want.
https://datatransferproject.dev/
The Future of the Web
I recently spoke at a small conference we put on in Detroit. I talked about The Future of the Web, in the context of data ownership, and proprietary vs open platforms. It was the first time I’ve done a talk like this without slides of any kind, so I actually wrote out the whole thing (below). The live version was a little different, as you can hear in the audio (sorry it’s a bit echo-y):
On our current path, the web as you know it today will cease to exist. Ironically, the web of tomorrow will look more like the web of yesterday, when AOL and Prodigy were the way to get online. Everything will exist within a precious few walled gardens, controlled by even fewer massive corporations.
This is not how it was supposed to go down. The web evolved basically from the ground up on principles of decentralization, openness and freedom. “Information wants to be free” was the war cry of the early web.
Somewhere along the way however, a few big companies became very good at capturing and controlling significant portions of what happens online, and now we find ourselves on the cusp of a very different future than what many saw as the full potential of the web.
I’d like to talk to you about one possible alternative, based on my experiences thus far on the internet.
I’m 36 years old, and I started using the web heavily in about 1996, so about 21 years ago. That means 60% of my life I’ve been online.
During that time, a lot of my experiences, interactions, and created memories have happened purely digitally. Along the way, I got to wondering how many of those memories I could guarantee ongoing access to. How many of my own digital memories did I even control?
Back when you took a photo and had it developed; remember hardcopy photos? you had that photo effectively forever. You put it in an album, or in a box, or on the wall, and you pulled it out whenever you wanted to show someone else, or to look at it and relive that particular memory.
In the mid to late 2000s, the equivalent was a service called Flickr. Now, I’m no photographer, but I like to capture my own memories. I uploaded over 4,500 photos to Flickr between 2002 and 2014. Flickr went through some tough times in amongst a Yahoo acquisition and re-org, and I realized two things. One; I didn’t want to pay $25 a year for a premium membership any more, and Two; if I stopped paying, I would lose access to my own photos. My own memories.
That was the first light-bulb moment for me. The second came a few years later, when Twitter was exploding in popularity, and was having trouble scaling their systems. They decided they would impose a limit, which meant that you would no longer be able to access more than 3,200 of your own tweets.
I realized that by recording so many of my thoughts on someone else’s service, I had given up a piece of myself to them. If I had put my thoughts on a system I controlled, then I could choose if they were online or not. I could decide who had access to them. Since I had published them on Twitter though, those decisions were no longer mine.
The final lightbulb was Delicious. Delicious is, still, amazingly, an online bookmarking or link saving service. I used it for years to store and annotate hundreds of links so that I could find and reference them later. Then they got bought. And shut down abruptly. And bought again. Their new owners brought the service back, and started significantly changing how it worked.
I wanted my bookmarks and annotations, but they were tied up in this unstable, changing-for-the-worse web service, with a very hazy future.
Between Flickr, Twitter and Delicious, I realized that if I wanted to retain access to my own memories, to the things I was creating online, then I had to act pretty quickly, since I was coming up on my 3,200 tweet limit, I’d soon have to renew that premium Flickr account, and who knows how long until Delicious disappeared for good. I had to get a copy of everything and put it somewhere that I controlled.
I had worked a lot with WordPress at this point, and I knew that tweets, links, and photos were perfect candidates to be published on a WordPress site. It even had specific concepts for them all, called Post Formats. I set out to build the tools that would allow me to reclaim all of my own content from other web services, and archive it to my own WordPress. A service that, thanks to its open-source DNA, I had complete control over, and knew was not driven by any specific, nefarious, commercial interests.
So I got to work, and wrote a plugin called Keyring that gave me the basic ability to connect WordPress to other online services. Then I wrote the specific systems I needed to import my content from around the web, and since then have expanded that to reclaim…
- 14,000 tweets from Twitter
- Those 4,500 photos on Flickr
- 6,000 check-ins on Foursquare/Swarm
- 1,700 bookmarks from Delicious
- The full text of 1,300 articles read via Instapaper
- 700 Instagram pictures
- The details of 200 trips from a service called TripIt
all of that going back to around 2002
Today I have 29,000 entries in my personal archive, compiled from all those sources, plus around 300 of my own full length blog posts.
Now this is perhaps an interesting personal story, but you’re probably wondering how it’s relevant to businesses, or for that matter, anyone who’s doing more with their life than posting photos and tweets on the internet.
It’s relevant because today, we see advertising campaigns that end with a facebook.com address. It’s relevant because small businesses are relying on their Yelp ratings to attract customers. It’s relevant because without Google Local listings appearing in a mobile search, you don’t exist to your own neighbors.
I believe that some of the same concepts of data ownership and control we’ve talked about, are critical to the healthy future of the web, and the world it interconnects, whether we fully appreciate it yet or not.
The problem with the way we’re headed today is that while Facebook, Google, and Yelp are all global, multi-billion dollar companies that are probably not going anywhere soon, they’re providing their services 100% on their terms. Not yours. You are welcome in their playground only so long as you agree to, and abide by, their terms of service. You often don’t even own or retain full rights to your own data when playing in their playground. You’re renting a storefront in their marketplace. You neither own, nor control, your own online existence.
So if we use some of the technologies and approaches I mentioned earlier, what does that look like for a business today? How can we shift some of that control back to you? Give you the freedom to make your own choices?
Well, you probably already have a Facebook Page set up for your business, so maybe you can connect that to a fresh WordPress. It pulls down your visual branding, opening hours, and contact details. It uses that as the seed data to automatically set up a simple website.
Now you’ve got your website, powered by WordPress, which you fully control. You bought your own domain, so the site is at a web address that you actually own. No one can decide you’ve violated some terms of service and kick you off. No one can take your address away from you. You can customize the design of your site, use a different theme, add functionality with plugins, the sky’s the limit. No one gets to dictate what you can or cannot do; it’s like instead of renting, you bought the whole building where you’re going to set up your store, and you don’t need a construction permit to fit it out how you’d like.
But the magic part is that when you imported your data, you created a 2-way connection between your WordPress and Facebook. Now you update your opening hours in WordPress, and your Facebook Page is also immediately up to date.
You add new connections to Google and Yelp, so we automatically create listings on those services, and keep them up to date with your site as well. We download copies of your reviews automatically, send you push notifications via the WordPress app when there are things that need your attention, and allow you to interact with the community you’re building via your Instagram account, right there in WordPress. Your content is pulled into your own site where you can exercise complete creative control over it, and use it in ways that Instagram would never dream of, nor necessarily allow.
WordPress becomes the hub of all your online activity. A central place that you control, where you both aggregate and interact with your digital presence. You choose whether it’s presented as a slimmed down, utilitarian tool, mainly for providing information to other services, or a complete and beautiful destination, where potential customers can find whatever they need to know about your business, transact with you directly, or interact with the community you’re building.
Today, you choose the direction you’ll go in. You can choose to rent space on one platform or another, or you can choose to actually own your own piece of the web. You can choose to participate in these business-critical, closed platforms, but to also build your own separate online presence, which you control and define. You choose whether to tie your future to a walled garden which dictates the rules of engagement to you, or to invest in an open platform, which allows you to grow and change but still be a part of the fabric of the web. You have the freedom to choose.
Personal Location Tracking
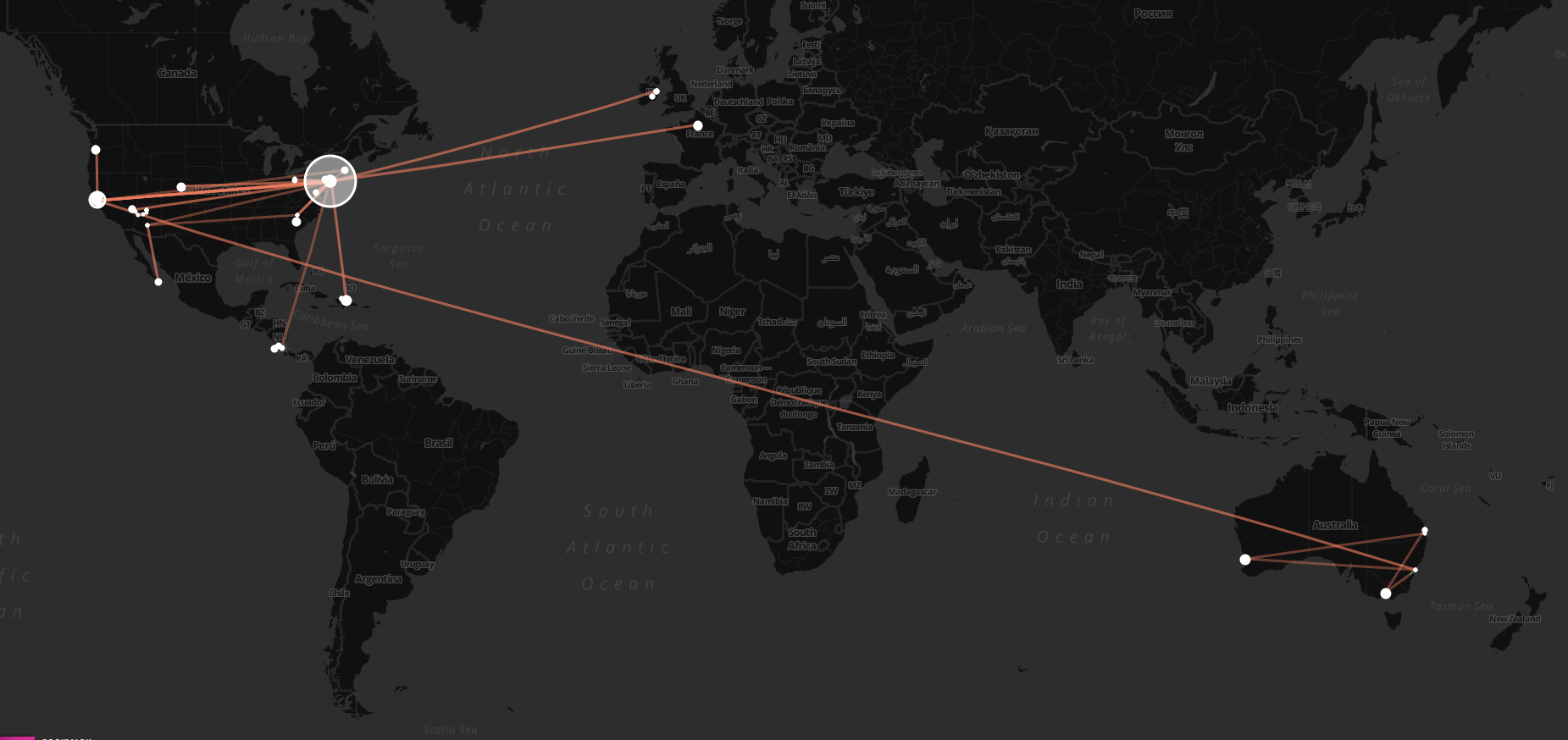
I’ve been pretty fascinated with the idea of recording my own location for a while now. I started using Foursquare at SXSW in 2009 and have mostly continued to do so since then (I have over 3,700 check-ins). You can see my check-ins being syndicated back to this website (using Keyring Social Importers), and if you scroll back through the history of the main page, you’ll get maps aggregating a few check-ins at a time.
TripIt helps me keep track of all (most) of my travels, and provides back some data (via API), which I also import into this site. Here are all of my trips since March, 2008.
In February last year, I started using Moves, and quickly came to love its simplicity. It’s a background app that runs on your phone and keeps track of your location. Using server-side data processing, they crunch the raw location information to figure out when you were walking, running, riding, or on some form of transit, then give you back a timeline and a map showing what you’ve been up to. It’s a really nice “set and forget” way of keeping up with how many steps (roughly) you’re doing each day, plus your other forms of exercise. The app has continued to make small improvements, and then on April 24, Facebook bought them. I can’t say I’m stoked about the acquisition, but regardless, it’s a cool app, and it collects some fantastic data.
Since it’s all data, and there’s a growing sphere of location/movement-related data services out there, shuffling your data around is just a matter of a little programming. As I mentioned, I’m importing my Foursquare data into my blog already. I also have a Moves importer that’s currently creating a text-only summary of my information. I’ll probably add simple maps to it at some point. Moves-Export is a pretty neat service that will automatically import your Moves data and can give you a better breakdown of things, plus auto-post to Runkeeper and Foursquare (if you like) when activities are over certain thresholds (e.g. riding for more than 15 minutes). Pretty awesome.
Today, Chris Messina tipped me off to Move-o-scope, an awesome web app that will slurp in your Moves data, and give you back a rich visualization of it all. It lets you toggle things on and off, pan around the globe and see what you’ve been up to. It’s fascinating. Here are some places I’ve been since last February!






It’s fun to turn on the “Transit” layer (orange/brown, seen in the last picture above and the first one in the post), and follow the lines around the globe to see where you’ve been, then turn it off and zoom in to get a feel for what ground you covered while you were there.
React
"A JavaScript library for building user interfaces", built by Facebook/Instagram.
SharedCount: Social URL Analytics
SharedCount: Social URL Analytics
API (and details) on the number of times a URL is shared on Facebook, Twitter, Reddit, LinkedIn, Digg, Delicious, StumbleUpon, Pinterest and Google +1.
Jetpack 2.0, Packed With Magic
![]()
Last night, I preemptively tweeted about the upcoming release of Jetpack 2.0:
I can't wait for the very-near release of @jetpack 2.0. It is loaded with awesomeness and magic.
— Beau (@beaulebens) November 7, 2012
Where is Your Digital Hub/Home?
I’ve been using WordPress to power my own website for a while now, and working with it in some way or another for even longer. Over the years, I’ve developed the belief that it’s a pretty perfect platform for people to build their own “digital home on the web”, considering the range of plugins and themes available, the flexibility of the publishing options it offers, and the fact that it’s completely open source, so you can do whatever you want with it.
That last bit is important in more ways than you might immediately think. Apart from just being able to write my own plugins or tweak my themes, this also means that I own my own data. I think in this MySpace/Facebook generation, people are all too loose with the data trails they create — giving up ownership of their digital self at the drop of a hat. In case you didn’t realize, when you use something like Facebook, it is not the product, you and your data are the product.
List of Facebook fb_source values
If you’re working with Facebook’s API and trying to record some stats around the values being sent via their fb_source parameter, you might be forgiven for thinking that you could get a definitive list of valid values from their official documentation. Hah! Think again.
foauth.org
“OAuth is a great idea for interaction between big sites with lots of users. But, as one of those users, it’s a pretty terrible way to get at your own data. That’s where foauth.org comes in.” Use HTTP Basic to access OAuth-protected data via a proxy-API.
Open Graph Parser
A PHP library based on an RDFa parser, for parsing Open Graph tags out of a webpage/string.