
How to avoid the Migration Trap | Bruce Wang – Director of Engineering at Netflix
Hey there! We’re still getting things figured out with Substack. Still, I’m happy to see we’ve received tremendous feedback on our first piece of content (Coda’s head of engineering’s tips to 10x your engineering execution)!
In this second in-depth article, we invited Bruce Wang, Director of Engineering, Product Platform Systems at Netflix, to share his views on the “migration trap”. But first, a bit more about him 👇

Bruce Wang, Director of Engineering, Product Platform Systems at Netflix
“Trusting teams, seeking excellence, driving customer delight.”
This is Bruce Wang’s motto. And when you’ve known him for as long as I have (6 years, I guess?), you know it’s not just the usual BS. And maybe a reason why he was a speaker at our… no-BS conference.
Bruce is a Director of Engineering at Netflix, where he leads the Product Platform Systems team, working on various high-leverage systems such as API Infra and DevEx that power internal and external product experiences, Product Data Systems that handle product telemetry and logging data, and Tech Lifecycle Innovation focused on shared tooling, tech debt innovation, and legacy systems operations. With 23+ years of experience in the software industry, he’s spent the last 11 years as an engineering leader and founded two companies during the journey.
I’ve always found that Bruce brings the best of both worlds. At the same time, he’s the smiling, joking, and outgoing person who makes the workplace more entertaining; and he’s the one who can retreat, put a lot of thought into high-level decisions, and work (crazy) hours to see his vision come to life. A bit like the frivolous Bruce Wayne, and its work-hard, bring-his-vision-to-life counterpart: Batman.
But what I like even more about Bruce, is that he thrives most when he sees people around him grow and embark on insightful journeys.
His talk at Elevate (see above) was about one of these journeys: the migration from REST to Falcor API, Netflix’s in-house graph query language, to GraphQL. A journey with highs and lows, and many learnings he shared on stage at Elevate. A journey that can be a real nightmare if you fall into what he calls the “Migration Trap”.
Without further ado, I’ll let Bruce take over and dig deeper into how they (try to) avoid the migration trap at Netflix. Let’s go!
For more from Bruce, follow him on LinkedIn or read his leadership philosophy.
How we (try to) avoid the technology migration trap at Netflix
The Innovation Lifecycle
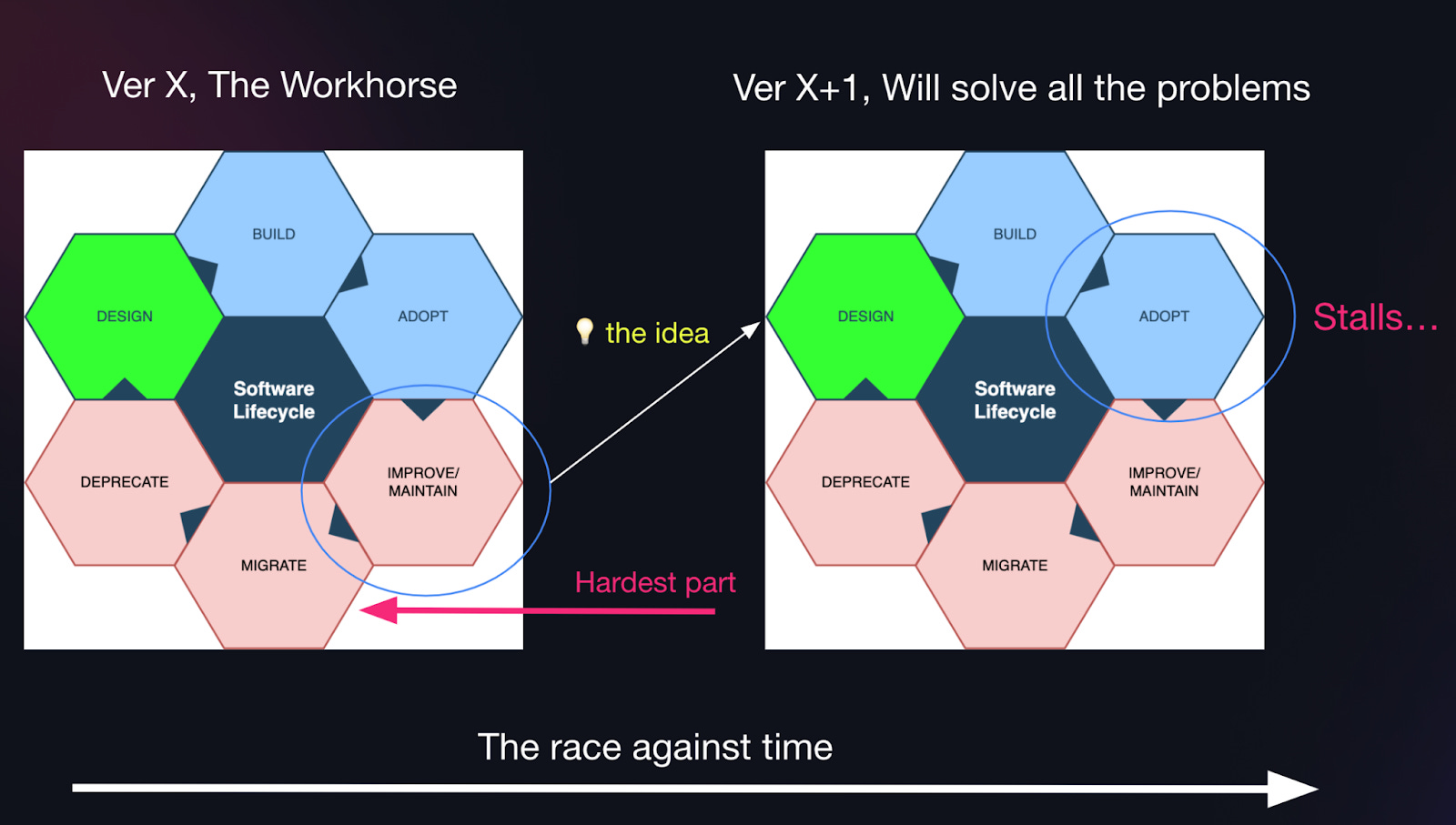
When talking about the software innovation lifecycle, I like to use the graph below: innovation is a dynamic and cyclical process, that comprises various steps:
-
Design: the initial stage where new ideas and solutions are conceptualized.
-
Build: the practical phase of constructing the designed system or technology.
-
Adopt: implementation and integration of the new system into the existing environment.
-
Improve and Maintain: ongoing efforts to enhance and sustain the system’s performance.
-
Migrate: transitioning from an older version or system to a newly developed one.
-
Deprecate: the final phase where outdated systems are phased out (or parked!).
The lifecycle always starts with designing and building a system, but the challenge often lies when new vs. old systems intersect at adoption and migration.
Let’s say you have the current version, let’s call it V1, or “the workhorse”, it is something that has gotten you this far, but it has run its course… And you have a new idea: what if we could solve all the problems and make some big improvements? This is usually where the V2 idea comes about, and you start designing and building that prototype. There’s a lot of excitement and energy on the new shiny option, but when you hit the adoption phase, this is where reality sets in. Migrating off of v1 and gaining traction on v2 can be extremely hard.
This is where you run into the “Migration Trap”.
The Race Against Time
In my experience at Netflix, I’ve come to realize that managing the tech lifecycle is essentially a race against time: the decisions you make today will usually have a huge impact on your organization tomorrow.
When it comes to migrations, the industry is well-versed in building large systems that can handle millions of requests, or processes to support thousands of engineers.
But most teams overlook another crucial factor: time. A migration can be appropriate at one point, but if it takes too long to release, you are just bound to create more tech debt, and friction among all teams.
“Take any great technology and add 10 years to it. It’s gonna suck.” – Bruce Wang
The clock is always ticking:
-
Technologies evolve, and what was the pinnacle of innovation at some point will just be obsolete a few years apart. What works today may not suffice tomorrow, or will stop being maintained.
-
The more time your lifecycle takes, the higher the chances that leadership changes. With a new leadership usually come new ideas or new ways of solving a specific issue.
-
The teams themselves undergo changes, and new team members will have a hard time acquiring context and ramping up.
-
Business priorities shift, and what was the focus in the past just becomes a side quest.
-
Sometimes, the new feature you built just doesn’t work. It doesn’t solve the problem you designed it for.
A migration just becomes a relentless pursuit, and the race isn’t about deploying the latest technologies, but ensuring that the system you designed doesn’t fall behind the curve.
One example is when Netflix built a graph API, and a graph language called Falcor, that we used internally. A short time after Netflix deployed it, Facebook released GraphQL. We bet on that huge, internal, and open-source tech, only to see GraphQL get adoption, traction, a big community, and the coolness Falcor lacked. All of a sudden, it became the hottest thing since sliced bread.
We wanted to create an API architecture that was more flexible and efficient for our teams, and, let’s be honest, GraphQL did the job better. We thus decided to migrate our iOS and Android Apps from Falcor to GraphQL.
To give you some more context, here is a timeline of significant API events for us. Spoiler alert: the migration took us close to seven years.
-
2007 – Netflix announced streaming
-
2008 – We launched our Open API – aka REST – v1.
-
2012 – We started migrating to API .Next – v2.
-
2014 – We shut down our Open API
-
2015 – We released EdgePaaS – the new Platform powering our Falcor query-language API – v3. The goal, here, was to create a new UI development framework for our Client facing APIs
-
2021 – We began work on Consumer Edge (our GraphQL API) – v4
-
NOW – We completed our .NEXT -> EdgePaaS Migration, but now in the middle of our EdgePaaS (Falcor) -> Consumer Edge (GraphQL) migration
We’ve learned much along the way, and I’ll share the principles that make a migration successful right below.
Enjoying Bruce’s insights so far? Subscribe to get all of our posts in your mailbox
3 Principles for Successful Migrations
1 – Plan & fund
That principle might be obvious to you, but everyone falls into the trap, no matter how well-informed they are: you get what you pay for.
In other words, there are huge chances that you will underestimate everything in a migration: how many issues you’ll stumble on, how many people you’ll need to make it successful, how many implications it has that you haven’t thought about, etc.
So, what I usually advise is to first, have a focused effort on the migration: in many strategies I’ve seen in the past, including some I’ve been a part of, we didn’t account for all the work, and people needed to work on the migration. You need a team to focus on the ins and outs of the migration, right from the start.
Second: It’s a tautology, but something we also often don’t account for is that you can’t plan for uncertainties. So, when you first design your plan, there are chances that you’ll decide on a hard release date. With a hard date, expectations from all stakeholders will be incredibly high. If you don’t deliver at the exact moment you announced, chances are that your team and you will just look bad. But besides this, early on, you won’t be able to assess exactly how much time it will take. You can guesstimate, but you just can’t know precisely when you’ll complete your migration.
I believe you should use completion dates strategically instead. For example, set a date for when you’ll get the first customer onboarded. Even if things aren’t 100% complete or perfect, this is something you can achieve. Set the dates for tactical items.
One last thing we often overlook during the planning phase is answering that one question: what will we do with the old system? You should thus have a precise plan for the old system: deletion, strategic parking, unplugging it step-by-step, letting both systems live at the same time, etc. We’re so often projecting ourselves into the future that we forget to plan for the legacy items.
Hence, one part of the planning can be to ensure a smooth transition, eg. through intermediary steps (aka a bridge solution), that will help us migrate while maintaining the older system. In our case, we had two bridge solutions, one a temporary system a partner team built so they could prototype GraphQL before we were ready, and another more durable bridge solution to help decouple core logic in v2 that can be shared between V3 and V4, and avoiding our latest stack from be coupled from our previous generation (which happened when v2 -> v3 took too long)
“If engineers embark on a new project with excitement, without proper planning and funding for the migration, they will just create more tech debt.”
Effective planning and staffing are fundamental to any successful migration project. However, this process can be time-intensive and resource-heavy. Inadequate planning can lead to years of wasted effort or, worse, relegation of the migration to the graveyard of unused technologies.
And there’s another essential prerequisite: proving it’s all worth it!
2 – Prove significant value
Let’s go back to MBA classes for a minute and talk about Porter’s Five Forces.
Porter’s Five Forces is a framework for analyzing a business’s competitive environment by evaluating five key factors: the threat of new entrants, the bargaining power of suppliers, the bargaining power of customers, the threat of substitutes, and the intensity of competitive rivalry.
We’ll focus on the threat of substitutes. It refers to the risk posed by alternative services that customers might use instead of yours. To avoid this and get a business advantage, some companies design for a high switching cost. If a user can’t switch easily from one service to another, it deters them from changing and increases retention. If you were a company offering an incremental 10% improvement compared to the current service your customer uses, there’s no chance they’d switch over to you.
You’ve got it: the same applies to technology. The higher the switching cost, the harder the migration will be. The complexity usually lies in the fact that the older system does a lot, and much of the migration costs are not borne by the team introducing the new system.
You then MUST prove a significant value increase. Your new system has to offer transformative benefits – something that the old system simply couldn’t do. Remember: time as a scale dimension is as precious a resource as your engineers or your technology. If you aren’t able to prove significant value, maybe you should ditch the migration altogether.
For us at Netflix, GraphQL represented a fundamental shift in how we approached building and managing APIs. It opened doors to possibilities that our previous system couldn’t handle such as giving mid-tier teams full control of their Consumer-facing Edge APIs. If your V2 marginally improves your V1, you might not migrate at all.
Most teams will likely start with small use cases, and prototype and build out some early use cases to build confidence, but a key counter-intuitive strategy after that is to tackle the hardest use cases early on. Maybe not first, but as soon as you can. When we migrated from our V2 to our V3 API, we had left the hardest canvas last. For Netflix, it’s our home page.
The hard-earned lesson was that many things we thought our new API could do well performed poorly. It couldn’t handle the scale and complexity of our home page. When we switched to V4 (ie. from Falcor API to GraphQL), the mobile team picked the home page first. It was scary, but the hardest part of our migration was the one that brought us the most insights. It also proved that if we could manage the hardest part of the migration, we could handle the rest.
This dovetails to the next strategy which is white-glove early adopters. In our case, we needed UI teams at Netflix to help us migrate from V3 to V4. So, we partnered closely with the mobile teams to help migrate the home page, provided exceptional support and attention, and worked closely with them to address issues. Your early adopters will likely run into the most issues as you’re still working through the kinks of your system (especially if you’re going after the hardest use cases), so before you can scale out the migration, make sure your new stack works well.
We could have chosen to put all the “migration pain” on the UI team, but we decided to fund a team to share in that burden. This also helped us understand the complexities of other parts of the system, and why in some cases a badly planned migration stagnates or never happens.
This approach also enabled us to get the first users and build trust in our new system. It helped us demonstrate its efficacy and refine it based on real-life use cases, setting a strong foundation for wider adoption at Netflix.
Another strategy is to vet your technology internally before going to partner teams or “eat your own dog food”. In our particular case, we built the first Consumer DGS (Domain Graph Service), so we learned how to run and scale that platform before federating the API to other domain teams. This in itself was a “bridge solution”, as we built the first API stack that eventually would be federated out to the appropriate domain teams.
When planning for migration, there’s usually another trap people fall into: aiming for feature parity. I believe you sometimes have to zoom out and get the bigger picture: is this new system an incremental improvement or a transformative one? If this is truly a new way to do things, you may not be able to compare it feature by feature. In these cases, the term “migration” is a bit of a misnomer as what you’re really working on is a reengineering effort. In our case, V4 not only was a complete overhaul of our client-to-server protocol (Falcor to GraphQL), but also a reimagining of our API development workflow moving away from bespoke per UI “BFFs” (backend for front ends) calling into a single aggregation tier to an unified GraphQL API powered by disparate domain APIs.
As a quick recap, you can prove significant value using these tactics:
-
Tackle the hardest use cases early on
-
White glove early adopters
-
Dogfood your own technology
-
Don’t aim for feature parity
3 – Keep a learning mindset
When you’re part of the migration team, there’s some excitement about the new system. You envision the future in a very positive way. You think your work will solve all the problems you had until now. You’re happy you won’t have to deal with that huge debt on the old system. You’re sure everything will be amazing once you’re done!
That excitement is a great motivator, but remember you should be pragmatic, not dogmatic. Is your system really going to be better? Are those two years of painful work worth it? I’ll be frank, with our Netflix API migration, I sometimes wake up in cold sweats wondering if the effort is worth it or if our federation strategy will actually work. Is the workflow we’re building really that much better than before?
I don’t think this is a bad thing. You should always challenge your assumptions and wonder if the migration you’ve planned is the way to go. The first way of doing this is to focus on where your tech doesn’t work. You may have a bias and listen only to enthusiastic people, as it comforts you in your choice. Yet, I think you should embrace your skeptics. There are some “sparring partners” who will challenge you and nitpick. Listen to them and find solutions. You won’t be able to address everything, but those skeptics will help you improve your system.
In some cases, those skeptics will be right. The strategy or tech you chose isn’t the right one. And in such cases, remember that abandoning is NOT a failure. I’ll repeat it: be pragmatic, not dogmatic. Don’t fall into the sunk cost fallacy: you’ve invested many months or years into your migration, but it sometimes no longer makes sense.
You have to look at the outcomes you were aiming for, how far you got, and if it makes sense to continue. In our v2-> v3 case, we decided to “abandon” the migration for our Web UI, so we finished up to a certain point and then left it as is.
It’s your job as a leader to make the tough decision and abandon the migration. This abandonment can be painful, obviously, but can bring you great insights and help you build for future, better outcomes.
So, remember: plan your migration thoroughly, according to the intensity of the task; get buy-in by proving significant value in the migration; and keep your learning mindset until the end, no matter how invested and convinced by your solution you’ve been.
Wrapping it up
Migrations are tough. For many, it’s the least exciting part of the tech innovation lifecycle. And yet, there’s always a point in time where you’ll have to go through this step. And better sooner than later: you’re in a race against time.
As we’ve explored, successful migrations rely on several principles: planning and funding your team proportionally to the challenge, proving the migration has a significant value, and keeping a learning mindset all along the way.
High-performing software teams shouldn’t just be measured by the number of systems they create but by the migrations they finish and the systems they deprecate.
At Netflix, the stakes and scale are incredibly high. It’s common for our top senior engineers to lead migration efforts: when you’re faced with transitioning a system that handles 1M+ RPS to a new framework or technology, the complexity and potential risks are immense.
Yet, there’s one thing I can’t stress enough. I’ll write it in bold so you remember it:
Think about time as a scale dimension.
-
You’re in a race against time and must migrate before your technology is obsolete.
-
A badly planned or underfunded migration will waste your time, and the time of other teams, and will ultimately end up in the graveyard.
-
Your “reengineering” effort – and the time everyone will spend on it – is only worth it if you can prove it brings transformative benefits.
If tech innovation was a board game, designing and building would be the thrilling start of the adventure, full of excitement and possibilities. But as you progress, the game takes a complex turn, and you may fall into the migration trap. I hope this article helped you avoid common pitfalls and better prepare for your next lifecycle journey.
If someone transferred this newsletter to you (and you like its content), just click below to subscribe (for free!)
That’s a wrap – Hope you liked it!
Let us know what you think of this second in-depth article! Was it too long? Too short? Did it bring you value? Do you like the format? Was it actionable enough? What can we improve? We’re all ears 👇
What about the quality of the content?
What about the length?
Thanks in advance for the feedback!
Quang, Cofounder at Plato, on behalf of the Plato team
PS: the more, the merrier! If you found value in reading this article, you can share it in just one click: