
Giving More Tools to Software Engineers: The Reorganization of the Factory
2020-12-16
It’s a popular attitude among developers to rant about our tools and how broken things are. Maybe I’m an optimistic person, because my viewpoint is the complete opposite! I had my first job as a software engineer in 1999, and in the last two decades I’ve seen software engineering changing in ways that have made us orders of magnitude more productive. Just some examples from things I’ve worked on or close to:
- Spotify built a whole P2P architecture in C++ in order to distribute streaming music to listeners, something which today is a trivial problem (put the data on a CDN).
- I used to write custom mapreduce jobs to pull basic stats, then wait for hours for those jobs to finish. Today these would be SQL queries in a datawarehouse that would run in a few seconds.
- I once ran a web shop and spent a week implementing credit card payments. Today it’s 15 minutes using Stripe.
Not to mention the changes in developer processes:
- Unit tests were really rare in the industry — I first encountered it working at Google in 2006.
- When git was new, git-flow was the prevalent workflow, and many developers I worked with spent an inordinate fraction of their time (like, 20-30%) just rebasing.
- CI systems were fragile, CD basically didn’t exist, and deployments were scary manual affairs.
These are just examples — I could go on all day. Much like the classic No Silver Bullet paper on software productivity, none of these things in themselves were a dramatic improvement. But productivity improvements add up, and they add up on a logarithmic scale, meaning it’s not unreasonable that we see orders of magnitude of improvements when your time scale is decades.
(Note: I’m going to use the term “tool” throughout this post to refer to all kinds of things: frameworks, libraries, development processes, infrastructure.)
The insatiable demand for software
An extremely crude classification of the world is that
- There are some things that has great software
- There are some things that has mediocre software
- There are some things that has no software
This is pretty obvious so far, so I’ll keep going: if there was an ability to produce infinite amounts of software instantaneously at zero cost, the two last buckets would go away. Mediocre software exists because someone wasn’t able to hire better engineers, or they didn’t have time, or whatever. Things without software… it’s kind of everything? I mean, why don’t your shoes have a step tracker built in? Why does Mark in Accounting still generate PDF invoices and email them to clients? Why doesn’t… I could keep going.
We’ve obviously been going in this direction for a long time, and my point is that there’s so much left that can use software. Why hasn’t it happened already? Because someone made the economic decision that the cost of building that software was too high. It costs money and time to hire engineers and train them and getting things done. So how do we think about that cost?
Supply-demand of software engineers
Let’s go back to my points about software engineer productivity going up over time. In economic terms, it means that the value of the output per time goes up. On the demand side, it means that the cost of building software goes down. What previously used to take 1,000 hours now takes 100 hours.
If demand was fixed, it would mean mass unemployment and lower salaries for engineers, but demand isn’t fixed! As I’ve implied earlier, lower costs of building software means new opportunities open up. It previously wasn’t worth paying for 1,000 hours of engineering effort to build your gizmo, but it might very well be worth 100 hours. There’s enormous latent demand. You can even afford to pay engineers a bit more per hour.
These things can all happen at the same time:
- More software gets built
- Software engineer salaries go up
- The number of software engineers grows
This might be counterintuitive, so it’s worth contrasting this with something where demand is fixed. Let’s say some process is invented that increases the output of diaper factories by 10% (keeping all costs the same) and that invention is immediately available to all diaper manufacturers. What’s the result? There will be a temporary surplus of diapers on the market, and the market will converge to a new equilibrium where the supply shrinks to meet demand. In the process, some factories will close, and prices of diapers will go down.
The difference with software engineers is that demand grows when the cost goes down. Your aunt’s dental practice didn’t use to have a website, but now it’s worth having a whole online booking system. The school your kids go to suddently has an app to send updates to parents. I don’t know — my point is, with price going down, more demand opens up.
It’s not just across the whole economy that this happens, it can also happen at a micro scale. If you have a team of data scientists and you introduce a tool that makes then 2x more productive? Great — you just doubled the ROI of each incremental hire, and you should go and hire more people. I’ve never seen a company where data scientists run out of work: there’s always more things to analyze.
Will this go on forever? I guess in some end state, we’ll hit someting that looks like the singularity, where software itself builds software so fast that demand can’t grow with supply. That’s at the point where I’d be worried about software engineer unemployment. But for the next few decades, I think it’s a pretty decent bet that we’ll see the number of software engineers growing and growing.
How to become a software engineer
The growth of software as a field and the growth of salaries obviously in itself attracts more people to the field, but I think there’s also another thing that’s happening.
Decades ago, software engineering was hard because you had to build everything from scratch and solve all these foundational problems. You need storage to build something to serve 1M concurrent users? Wade through papers about consistent hashing, CAP theorem, CRDTs and what not, roll up your sleeves, and prepare yourself for 100,000 lines of hard core C++.
Today, these problems are “mostly” solved, and you can use off-the-shelf tools for most of it. It’s not easy though! Like I mentioned earlier, there is no silver bullet, and there’s a million tools out there, and you need to know based on best practices how to stitch it all together. But knowing this is a different type of hard.
Software engineering a few decades ago favored the people that were deep abstract thinkers — who could stitch together complicated software from atoms. To me it looks a lot more like a craft today — it’s a lot more about learning what tool should be used for what job. I mean, it still very much favors deep abstract thinkers, but relatively speaking, that skill is a smaller differentiating factor than it used to be.
I think this changes the equation on the supply side. The barriers to become a software engineers are different today, and it’s opened up a larger pool of talent. This unlocks new supply, which means even more software is created.
The software engineer role in the knowledge factory
Building software used to be, and still is, a very expensive endeavor for companies. At the average company, you still have a backlog that’s seemingly endless. The software side of the factory is still often a bottleneck of the company.
What do you do when you have a widget maker that’s a bottleneck in a manufacturing plant? You make sure that the bottleneck runs at full utilization at any time. This means you centralize the resource management of the widget maker — you put controls on the inputs, and put a lot of effort into making sure what widget gets made in what order.
Most companies still very much operates roughly like that. But, the companies that (in my opinion) have exceptionally productive engineering teams are organizing themselves in slightly different ways. They tend to decentralize prioritization, and work directly with product and business stakeholders in tight iterations. When a resource isn’t the bottleneck any more, you can achieve vastly higher iteration speeds by spreading out resource allocations to many different teams. I don’t mean decentralizing in terms of management to be clear. What I mean is decentralizing the backlogs into small teams that work directly on business needs.
In this model, you don’t have a marketing team put something on the backlog of the engineering team. You have a team of cross functional people who own acquisition, where some people are traditional marketers and some people are engineers. You can imagine this with almost any function throughout a typical company: customer support, finance, or anything else.
A historical parallel that I find super fascinating is why electricity took so long to change manufacturing. Factories in the age of steam engines were built around power distribution from the almighty steam engines. Energy was the precious resource, so it’s natural to think about manufacturing plants as built around energy distribution. Electricity changed this, and decentralized energy generation, but it took a really long time for manufacturing plants to realign and take advantage of this.
(Note 1: This isn’t a perfect analogy since steam power wasn’t just the precious resource, it was also hard to build small steam engines.)
(Note 2: The main point of the article I linked to is that innovations often take time to unleash productivity, because the first attempts to use the new technology often tries to retrofit it into legacy structures. For instance: internet first created DVD-by-mail, but the real internet-native innovation was streaming video.)
Bottlenecks in the knowledge factory
I’ve been talking a lot about tools that make engineers more productive, but that’s not the entire story here. There are clearly also lots of tools used by non-tech people to get their own things done, and that’s great! But I also see a huge amount of tools built so that people don’t have to work with engineers. Why? A few reasons:
- Iteration speed: The cost of explaining to an engineer what you need makes it not worth doing it
- The engineering resources are not available (or too expensive, or whatever)
- You just need a fraction of an engineer but that market does not exist
- There’s some special domain knowledge needed to build something
- Engineers are weird and smell funny
Ok, the last point was just a dumb joke. I think the other points cover most of it though.
Out of these, I think the first one (iteration speed) is a 100% valid reason. As an example, I encourage all business people to learn SQL so they can run queries themselves.
What I think is unfortunate is the second one (no engineering resources available). A lot of us have probably encountered manual pipelines of people sending around Excel files with macros, copy pasting data new into the spreadsheet every morning, or something similar. This is sometimes referred to as “shadow tech”. Had there been dedicated engineering resources, the total cost of building and owning those things would probably be much lower.
But the fact that non-engineers are building technology validates that there’s demand for engineers. At many companies, engineers just can’t keep up with the demand. So, through better tools, over time, more needs can be served. Companies at the forefront of engineer productivity will probably see less of these issues: engineers will be involved early on and work on business problems.
The third point (fractional resources) is probably true at small companies. If you’re a dentist, you’re not going to hire an engineer to build you a booking system. Luckily, they benefit from the increased output industry-wide: there might be a whole new ecosystem of dentist software to buy (because building it gets much cheaper).
The last point (special knowledge) has some validity. I often see business people building manual workflows that later get taken over and automated by engineers, as a sort of a first line attack squad to get a basic prototype running. The counterpoint is that with increased decentralization, engineers will increasingly develop subject-matter experience. A lot of companies have dedicated data science and data engineering resources to the HR and Finance teams, as an example.
The great productivity inequality
An interesting corollary of all of this is that it creates a positive feedback where some companies will fall behind even further:
- Lack of adoption of new tools means falling behind the companies leveraging those tools.
- Higher salaries for software engineers means these companies are priced out of the higher end of the hiring market.
- A failure to realign the factory means lower iteration speed.
- A lack of engineers means a temptation to adopt tools to build technology without using engineers, with associated costs that are much larger.
In contract, the companies at the forefront of this will see their software engineer productivity surge and the iteration speeds improve.
I have spent six years in the mortgage industry and I have seen these trends play out very clearly in front of me. The biggest laggards are desperately adopting RPA and duct taping together off-the-shelf POS and CRM software. The slightly better companies have their own engineering teams, but seem to fail to realign the process factory to be a tech-driven company. My company Better is implicitly a bet on everything I mentioned in this post, plus maybe a bunch of other trends as well.
Wrapping it up
This was a lot of words for something that I think could be put succinctly into a causal graph:
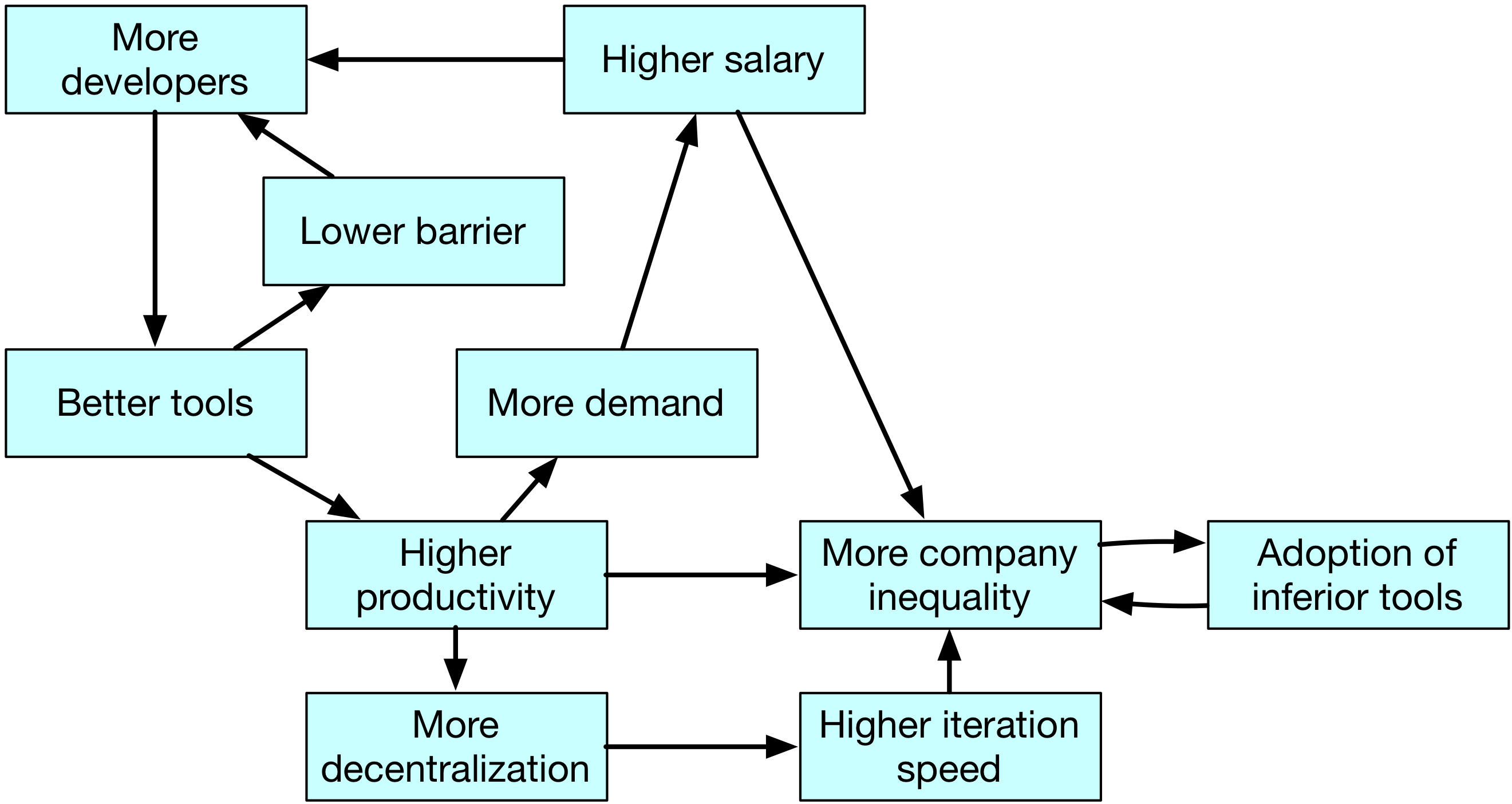
This is clearly not an exhaustive theory of everything that happens with software. There are many other trends, like internet erasing physical moats, and software creating more economies of scale. But this explains a lot of it, I think.
A theory is useless without an ability to generate forecasts or policy recommendations, so here are some things I would bet on:
- It’s a good time to be a software engineer
- The market for tools to software engineer will keep growing
- Many “legacy” companies will fall behind the productivity gains
- New entrants will threaten these companies and succeed to a large extent
- Every company should think about how to realign how they build technology to focus on decentralization and higher iteration speed, embedding engineers throughout the factory
- In the long run, it won’t be a good idea for companies to adopt tools with the only purpose of building technology without engineers
- Software engineers should wholeheartedly adopt tools that make them more productive: it makes them more valuable
- Companies with high productivity engineering teams will have faster-growing engineering team (because of higher ROI of hiring more engineers)
This blog post is a confluence of a number of previously unrelated thoughts in my head. Some of it might be super obvious to readers, some of it not. Hopefully there was something in the latter category you found useful!