
Reduce Friction – Ceejbot’s notes
The topic of reducing friction exhausts me: Do people still need to be persuaded to help their developers go faster? Really? In this, the year 2022? But yes, in this, the year 2022, many teams require persuasion on this topic. Or rather, their leaders require persuasion that they have to do more than give lip service to this principle, and that they must invest resources in making it so, and that those resources will not be “wasted” resources, not even for that person, you know the one, the official VP of Feature Factory.
Some leaders are not worried about wasting time, but are instead worried that devoting brains to this work will slow teams down. They admit that current processes are full of friction, but claim that they have to finish whatever they’re in the middle of before they should try to fix things. They think that reducing friction is a distraction from the real work. This approach is short-sighted. The best time to reduce friction for your team was the moment it came into being, and the second best time is now.
I’m going to cover three topics in this post. First, I’ll define what we mean by “developer friction”. Then I’ll make the case about why reducing friction is beneficial to engineering organizations, including benefits in areas I didn’t expect. And then I’ll go into concrete suggestions about how to do it, and the mindset that you need to bring to thinking about it. As is true with many other posts in this blog series, its audience is people who are technical leaders in their organization, but I hope anybody who wants to help their engineering org do better work can get something out of this.
Defining our terms
Let’s start by defining “process”. Process is the way you habitually do things. Do not confuse process with ceremony or formality, or any other term you’d like to use to describe overhead added to the core of the thing you want to get done. You always have process. You might not have thoughtfully-designed, intentional process.
“Ceremony” is a thing you do every time, ritualistically, usually involving other people. Regular meetings are a kind of ceremony. “Formality” refers to how prescribed and enforced a process is. When people react to “process” as a bad thing, they’re usually thinking of processes with heavy formality or more ceremony than they’re worth.
An example of a team process: “We prefer to have code PRs reviewed before we land them in main. It’s okay if docs or other non-functional changes don’t get reviewed and go directly into main.”
Adding ceremony: “All changes need to go through PRs, though we don’t require review.”
Adding more ceremony: “All changes must go through PRs with review, but we are okay if reviews are a rubber stamp.”
Adding formality: “We require that all PRs be reviewed & all CI tests pass before they can land in main, and we enforce this with settings in our source code repo that only administrators can change.”
Here’s a non-tech example of ceremony that might help you recognize it: pointing and calling. This is a ceremony that helps operators of dangerous equipment (most often trains) confirm to each other what the status of important indicators is. Station guards will point at an indicator showing which side of the train to open the doors on, and call out as they do so, making sure the train conductor knows which set of doors to open. Adding a ceremony to the process helps the operators avoid opening the wrong set of doors. Another example of this would be lockout-tagout. This formal ceremony ensures that people know when dangerous equipment is deactivated and can be worked on safely.
Let’s talk about “friction”, the main thing this post is worried about. Friction is increased in a process in each of the examples above. “Friction” is a useful metaphor here because each of those examples oppose motion: they demand more energy be invested in moving the project than would be required if they weren’t there. This might be a good idea! Lockout-tagout makes equipment safer to maintain. The lowest possible friction version of the PR example above is “we don’t care if code gets reviewed; merge right into that production branch.” You can see why adding friction in requiring PRs might be good for that team.
Adding friction is just fine when it buys you something worthwhile.
Teams with high levels of trust don’t need more than that first version of the PR process. Teams that don’t trust each other–or are perhaps required not to trust each other because of mandated security processes–need something more like the fully-formal version. A team that needs that fully-formal version will move more slowly than the first team. Is this worth the cost? It depends on the situation! Your goal is to identify your team’s work habits and work environment and identify things that are slowing everybody down without buying you something worthwhile.
Sometimes process is… well, ludicrous and obviously causing harm. This Twitter thread is full of pure, wasteful friction. Merely reading it raises my stress levels.
Let’s share tech stack horror stories: what’s the worst workflow or most absurd limitation you’ve hit with a codebase?
I’ll start: while working as a subcontractor, I wasn’t able to submit code directly for review. I had to attach the updated files to an email. 🥲
What’s yours?
— Jason Lengstorf (@jlengstorf) July 21, 2022
Process isn’t the only source of optional friction, and it might not be the most painful source. Instead, the work environment is often the worst source. The tools. The platform. CI workflows. Automation or, more likely, the absence of automation. Things that break and require human intervention. Buggy tools. Slow tools. Things people need to do often that are flaky. Builds that take forever and slow down develop-test loops. Continuous integration testing that takes a long time to run and slows down landing all work. Slow deploy processes that make the cost of pushing changes live high, and therefore makes pushing changes dangerous.
The other term we need to define is “toil”. The English word means “labor that tires you out”. In the context of tech world jargon, we use it to mean work that’s draining or time-consuming that doesn’t seem to be related to the core of what we need to get done. Repeated work. Predictable routine work. A process that is predictable and time-consuming but has to be done by hand is toil. Resolving Dependabot PRs to your repos is toil: it feels like work but accomplishes nothing worthwhile.
You shouldn’t tolerate either toil or tools misery. They are entirely avoidable, and they’re killing your team’s velocity and making everybody unhappy. Take stock of problems in this category, prioritize them, and eliminate them.
Making the case
You might think it would be easy to point to these sources of slow-down and say, “let’s fix things”. In practice, you might get pushback. Why? What can we, as technical leaders, do about the resistance to making things better?
First we must acknowledge that changing any system is difficult: systems are self-reinforcing for many reasons. People within the system see the cost of change clearly, but they often don’t have good ways to measure the rewards of change. Also (and let’s be honest here) all of us have lived through having change promoted to us as unalloyed good, then seen it turn out to be not so great. Or actively awful. People proposing change have a higher bar to jump over than people who want the status quo. So if you want change to happen, you have to invest energy yourself. You’ll need to make the case for action.
Why hasn’t anyone else made the case? Why is your team stuck here? Good questions! Remember that the people next to you in this situation probably hate the friction just as much as you do. If they could stop it, they would. Once again, we have to go to the system they’re in and look what what it reinforces. You, as an analyst of that system, have an easier time popping out of it and changing it.
Let’s look at some reasons why people around you might resist the push to make things go faster.
It didn’t happen overnight
The team might be unaware of how bad the problem truly is. They might not have noticed it was happening, because it probably didn’t get bad all at once; the slowdowns and the trouble got worse slowly over time.
To show how bad it is and break people out of denial, you might go to the data. How costly is the friction? Measure it! Count the number of times tool X explodes and the team wastes a day on cleanup. Graph how much time people spend waiting for slow builds. The data will help you prioritize, so it is not a waste. (I think gathering metrics on internal tools is a good habit for teams even when everybody’s happy.)
Ownership
The resistance to change might come from a far more human and emotional place. People might be attached to the things they built in the past, and reluctant to retire them. Don’t be a jerk about the software past versions of the team wrote. People do the best they can given the circumstances they’re in. Solutions that solved the problems of the past might no longer be good at solving the problems of the present. Honor the work done earlier, and let people feel good about it even as you’re coaxing them into replacing it. If you can, let them own the work of making their thing better. If that’s not possible, at least seek out their feedback and ask them what they’d do differently this time around. They probably have good ideas.
Sometimes people will block whatever work happens. They might want to retain control. They might be unable to admit they were wrong about something. The worse case I’ve seen was somebody who simply resented all authority telling them what to do about anything. Toxic orgs probably feature several people like that. Do I have to tell you what to do here? You don’t want to do it, because you’re a human being with empathy, but sometimes you have to fire people.
Stress
Organizations with a lot of friction might have people stressed by the work of pushing things forward despite the friction. Your most dedicated and motivated colleagues might be working the hardest to do this, and suffering the worst stress as a result. Stressed people can’t imagine adding to their workload by revamping existing systems that work, however poorly. They will resist change to protect themselves from their burdens getting worse.
This is an own-goal on the part of the organization. Leaders can prevent this, and indeed must. Stressed people don’t do their best work. Full stop.
Stressed people need to have their immediate needs honored and work shifted away from them. You must not listen to their opinions about what can and cannot happen until you’ve fixed their immediate emergency. Indeed, removing friction might give them the space to imagine a better world.
Don’t ask them to do the work of fixing their desperate situation. Fix it for them. This one’s on management, and maybe on you, o fellow technical leader.
Learned helplessness
The most depressing resistance to change comes from people who say that this is how bad it always is. They can’t imagine things being better.
Anecdote time! I once worked for a moderately successful but not quite successful enough startup that made a hardware thingie you might even have heard of. Eventually it was acquired by ConHugeCo Software, Inc, a very very very large company indeed that you’ve definitely heard of. The new corporate owners wanted their newly-acquired software team to work on project Foobar, already in motion. Foobar had a lot of existing process and tooling and a team that was already pushing it forward. They were behind. They were engaged in weird political machinations to create excuses, they were so behind. Surely this acquihired team could help!
Um.
Eventually I joined project Foobar, and I learned why it was behind. Getting a single commit into the source repo for project Foobar took at least half a day and sometimes an entire day. You had to get into line to check in. When you were head of the line, you had to resolve any merge conflicts that were caused by the people who merged in since you got into the line. (And no, this was not git.) You then had to build the full thing, and that was slow. Hours slow. Then you had to test. Then you could merge. Heaven help you if you broke the build: there were people who would get mad at you about that and penalties for it were discussed.
“Why,” I asked somebody, “do we not have a build team making this faster and better?”
The answer stayed with me. It was: “Nobody wants to be on a build team. They get laid off when their work is finished.”
Laid off. Their work. Finished. Uh. What?
The culture gap was epic and unbridgeable. The project turned out to be a famous disaster. Are you surprised? No? None of us at $acquiredCompany were surprised, either. The acquiring team could not imagine healthier processes. The cudgel was their only tool. They did not fix anything because that’s the way things were.
This is learned helplessness. Reject it. Things can be better than that. It is not only possible but normal for things to be better. I know that. You know that. Stand up for it.
If you can’t, leave.
The positive argument
Let’s make the case with more positive arguments. What will you get by relentlessly reducing developer friction? The obvious benefit: the whole team will go faster. I have to call this out explicitly, because a lot of the pushback to the idea of reducing friction comes from not thinking about what this means.
Everybody. Goes. Faster.
Reducing the amount of time it takes to do something by a couple orders of magnitude can have radical effects not just in kind but in category. When it took many minutes do download a single MP3 file, nobody was streaming movies. Now that gigabit fiber is an option for many homes, we’re streaming high-definition movies on a whim. Things you couldn’t imagine happening before become normal. You can probably think of more examples like this.
Here’s a modern example I’ve lived a couple of times now:
Deploys become fast: the cost of making changes is now low.
The cost of making changes is low: people become less fearful of making changes.
Less fear: changes get smaller and more frequent.
Small, frequent changes: less dangerous inherently, so failures happen less often.
Failures happen less often: the team becomes more confident.
A confident team experiments and pushes themselves into trying new things.
Everything gets better.
This is a virtuous cycle. This particular virtuous cycle can be promoted in lots of ways–great CI for instance–but hey, even CI benefits from running fast. And frequently. And easily from a developer’s laptop and not just a a remote process if you can wrangle that one. A barrier to doing something is a kind of friction too!
Friction is frustrating. It generates stress. Nobody enjoys slogging through a ceremony they can’t see the benefits of. Nobody enjoys watching a deploy fail again in the same way as the previous five times this week. Friction without payoff makes people unhappy. To my mind, this is reason enough for fixing it. Content people who are comfortable and talking regularly with their colleagues do great work; unhappy teams spend their time fretting about their unhappiness. The world is stressful. Don’t add to it. This is ethically good as well as pragmatic for whatever your shared venture is.
Let’s make a more banal, money-based argument next.
Salary is, for most companies, the single biggest cost they have. Stop wasting that money! Why are you spending money making your programmers do things by hand that could be done by a small shell script? This is overall a complex topic, and a lot of things factor into your decision to build, buy, or do nothing. Here, we’re most likely talking about build OR buy vs doing nothing at all. A fast calculation of salary hours vs payoff is useful for deciding when act as well as when not to act. Make a rough estimate of how much time your team is spending wasting on waiting for builds (fixing something, pushing a repeated process by hand, etc.) for the entire year, then compare that to what you’d invest into a single push into making that faster.
Once again, measurements help to inform your decisions. If you don’t have data, do something lightweight to get it.
Things to try
You are convinced! You have convinced others! You are able to act to reduce your team’s friction! How do you do it?
Start by asking your team what is slowing them down. They will straight-up tell you what’s wrong. Listen to reports of irritation; if the irritation rises to the level of frustration pay special attention. You might not take your team’s proposed solutions at face value. Here your team is like any software user, who will tell you all about the solution they’ve imagined, not the best solution you might provide. Listen to what people are trying to do and why they’re being prevented. Pay attention to the reality of their stories. Question everybody’s assumptions about the way things have to be, including your own.
Imagine what you would do in the ideal case, if you were designing the thing from scratch today. Take a step toward that ideal from where you are now. This is possible.
If you’re using bad software, stop.
Is your system configuration software driving you nuts? Switch to something else. (It will drive you nuts too, but perhaps less nuts.)
Is X famous SAAS thing that was super-cheap to buy driving your team nuts? (I’m looking at you, ubiquitous but relentlessly mediocre famous suite of tools.) Switch to something else.
Has your team staged a revolt and started using something that isn’t the official choice? Listen to the pain of your team. Honor the pain. Switch to their choice. This isn’t about allowing chaos to reign, but about paying attention to existing signals, and paying especial attention to strong signals.
Make team software changes definitively and without half-measures. Commit to the change. Retire the old stuff. Plan a cutover if necessary so you don’t leave mess behind: do any required data migrations. Get feedback on the results. You shouldn’t make changes like this on a whim unless the cost of change is pretty low, but doing it on the worst offenders can be a huge morale boost.
Treat internal tools as important software.
Work on internal tools is highly-leveraged: every one of your developers will write better software when their tools are good. It is worth devoting senior engineering brains to them. It is worth devoting your brain to them if there is nobody else. Your job, o fellow technical leader, is to make your team successful at building the widgets your organization wants to build. We must do the things nobody else can do.
If using an off-the-shelf tool isn’t possible, then the tool you’re building is critical to your product. Treat it like that. Take the work seriously. Design it thoughtfully. Do your usual requirements analysis! Who’s using this tool? What are they trying to do? What are the performance and latency requirements? How should errors be handled or reported?
Sweat the output of internal tools. Don’t bury important results of CI in a rubbish heap of uninteresting compiler output. Tufte’s design principles apply here too.1
Doing this analysis on testing system output was super-fulfilling and helpful for the consumers of the test output.
Common tool areas for you to think about:
- Chat and video conferencing software: is it reliable and high-quality?
- Bug/issue/task trackers: help or administrative burden?
- Source control software and tooling around it.
- Development environments: setup of any common software that your team needs to use. Examples would be specific versions of a language runtime or compiler needed to develop software.
- Internal tools that solve problems specific to your internal workflows.
- Build systems, both for the develop/test loop and for release processes.
- Deploying software. Is it fast? Is it reliable?
- The substrate upon which software gets deployed.
- Automated testing, particularly integration testing.
Distribute internal tools in compiled, packaged form. Don’t make people build/install them every time they need to use them. Have enough release process for these tools to ensure they work. Consult user convenience, not developer convenience here. (The needs of the many, etc etc.)
Treat your processes as worthy of thoughtful design.
I mentioned earlier that you always have process, because process is the way you usually do things. Think about your processes and tweak them as needed to remove unnecessary friction from them.
Water runs downhill. People always do the thing that’s easiest to do. Your goal is therefore to make the right thing to do the easiest thing to do. If people are regularly doing any end-run around a process to get work done (say, regularly asking for rubber-stamp PRs so they can be unblocked), you have a process that’s not earning back its energy cost. Fix it.
What are the goals you want a habitual-way-of-doing-things in an area to achieve? What values do you want to express? Be clear about them. Be clear about the priorities of your values. You might need to honor high priorities and let lower priorities go unfulfilled.
Make sure you have a feedback loop somewhere helping you evaluate your new processes. Designing processes without feedback from the lived reality is possibly worse than not designing them, because you’ll have people held accountable for doing things that turn out to be bad ideas. Iterate. Improve. Nothing need be set in stone. It’s okay to change! It’s okay to look at where people are walking right now and pave those paths. It’s a decent starting point.
Jump out of the system and examine its assumptions. One way of reframing the “I’m blocked by no PR reviewer here” problem is to notice that the person who’s blocked did the work alone and has no team or buddy who shares context about the work. If they paired, they would have an instant PR review, and a pretty high quality one.2 If the work was planned work and review was blocked, perhaps time for reviews should be budgeted into your team’s plans.
The best process is one that your team doesn’t even think of as a process because it’s been automated into invisibility.
Automate.
Obliterate toil: automate it.
Automate ruthlessly. This is where I have seen the most surprising pushback. We’re programmers. Automating processes is what we do! People will flinch about this, afraid of time spent automating things that won’t pay off. Yes, we’ve all been there. So don’t do that. Don’t automate things that are really one-offs. If there’s any chance you have to do the same thing more than five times3, automate it. If it’s complex and difficult for a human to do, automate it. If the blast radius of the explosion caused by a human doing it wrong is large, automate it. If the end results need to be the same every time, automate it.
Infrastructure should be automated as far as you can push it.
The upside of automation is that the software that does the work for you can be instrumented.
Measure and observe.
This is a corollary of deciding to treat your tools as important software, but it’s worth calling out.
Measure everything, and make the results of the measurement visible. Measure how long a process takes. Measure how long PRs sit unreviewed. How long each step of a deploy takes and how many deploys fail. Make all of this data easy to look at.
Instrument your tools so you know how often people are using them, how long the runs takes, and whether they succeed or fail. (Don’t instrument so heavy-handedly that you slow them down.)
My favorite way to do this is to use Honeycomb to trace everything, not just our production software. At a recent job we instrumented builds, deploys, and CI runs this way. The output of those runs prominently included links to Honeycomb’s visualizations of the traces. Every build and deploy report included a link to a view like this about how long it took:
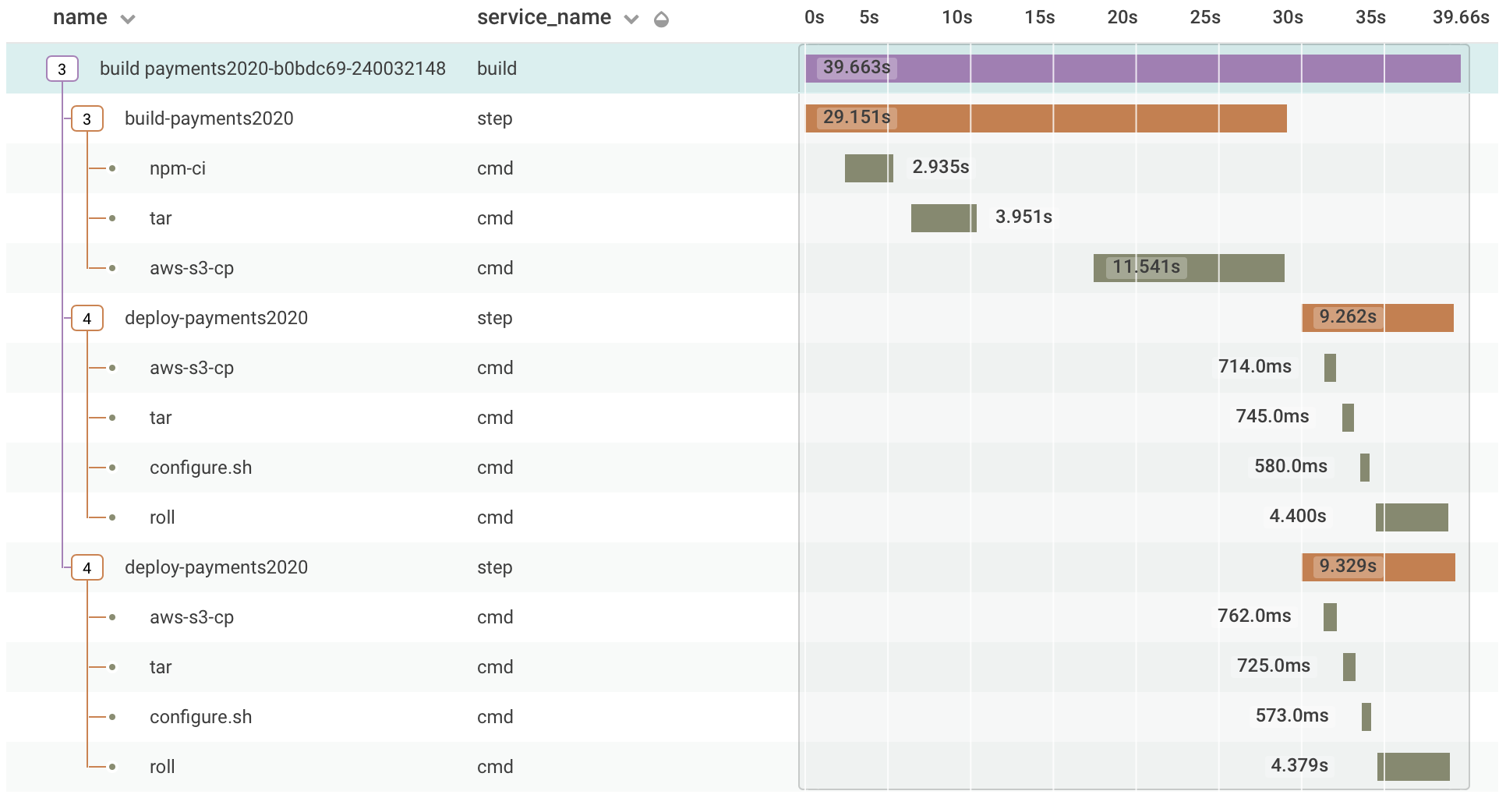
Is this deep? No. Did it take a long time to do? Also no. Is it helpful? Definitely yes. Imagine this, for everything. Imagine this, telling you about timings for every single internal tool you run, including the exit code returned and who ran it. Imagine how much better you can make every single tool your team uses with data like this.
You might have another tool you like to use here, which is great! Please tell me about it on Twitter!
The deer, they are teal
Here’s what I’d like you to take away from this blog post.
- Friction is slowing down your team.
- The energy cost of overcoming friction needs to buy you something worthwhile, or it needs to be reduced.
- Investigate friction by talking to your team. Frustration is an important signal.
- Observability isn’t just for your production software: measure everything. Use data to inform your decisions.
- Order of magnitude changes in cost result in entirely new behaviors.
- Design your processes.
- Design your tools.
- Automate ruthlessly.
- Set up feedback loops so you learn what’s working and what’s not.
Most importantly, you can fix it. Every little bit you fix gives you more energy back so you can fix the next thing. It will be worth the investment.
My thanks to Chris Dickinson for the lockout-tagout and pointing-and-calling examples! Also my thanks to David Zink for editing my prose into a tighter form.
-
Tufte’s design principles, recapped because they are so good:
- Above all else show the data.
- Maximize the data-ink ratio.
- Erase non-data-ink.
- Erase redundant data-ink.
- Revise and edit.
He’s talking about visual design, but this works for writing as well.
-
To repeat myself: PRs are best used to socialize work that’s already in a good state, not to find bugs in work somebody has already decided is finished. In other words, the useful review and tightening should happen before the PR process, in some earlier phase. Pairing is good. Strong testing is good. Team discussion about ways of solving a problem are good, so the approach taken in a PR doesn’t need to be debated. The PR is to say to a wider audience: hey, this thing happened. An exception to my own approach: small, uncontroversial bug fixes are perfect for review in PRs.
-
I kinda want to say “three times” here instead of five, but you know, use your judgement. Do a little basic arithmetic on how long a thing takes and how often it’ll need to happen. Think how important getting it done consistently is. Prioritize to match.