
Four Magic Numbers for Measuring Software Delivery

If you’ve read my previous post around ONZO’s engineering manifesto you will get a sense that we are proud of both our team culture and the way we deliver software. Late last year we started having conversations around “how do we elevate what we do to the next level as the team grows?”. Namely increasing our speed to market with new products while keeping a good grip on quality. We were using velocity as a planning tool, tracking quality through escaped bugs, had a handle on platform SLOs and working around a well formed roadmap. It felt like we were at risk of stagnating though.
I think the office Alexa must have been listening! Only 2 days later Amazon popped up with a recommendation for the excellent “Accelerate: Building and Scaling High Performing Technology Organisations” by Forsgren, Humble and Kim. Fast forward another month as I’d had time to read, ponder and could see how the contents may be the answer we were looking for. In this blog post I’ll provide a TL;DR of the book, detail how it has changed our approach and outline what we plan next

“Accelerate” won’t suit everyone’s tastes. It is, in effect, a write-up of 5 years of research through Puppet’s State of DevOps Report drawing conclusions where there is correlation between certain software delivery capabilities and high performing organisations. This means it’s a little light on the practical detail of how to develop the capabilities and pretty detailed on “showing the working” where there is a correlation. It posits that there are 24 capabilities that are correlated with high performing software delivery organisations. Broadly speaking these fall into a few categories;
- Continuous Delivery — How well do you build small batches, test them and push them to production frequently? Like… Really frequently
- Architecture — Does your systems architecture empower teams to work independently and deliver features end-to-end?
- Product & Process — Are you building the right thing? And learning how to do it better
- Lean Management & Monitoring — Is your approval process for moving a binary to production lightweight and effective? Once it gets to production how well does your platform share its operational health?
- Cultural — Does your environment support people in learning, growing and collaborating? Does the leadership inspire, support and provide vision for the team?
Reviewing these capabilities the team at ONZO can definitely say for some “yes we do this well” and for others “we could do better here”. Without actually being able to measure & capturing data around performance, how would we ever have the data to know whether we are moving the needle in the correct direction? The metrics suggested by the book are;
- Lead Time — The time it takes to validate, design, implement and ship a new valuable thing
- Deployment Frequency — The number of times per developer per day we ship to production
- Change Failure Percentage — When you deploy to production so regularly, do you keep breaking it? Signs of change failure could be red deployments, bugs, alerts etc…
- Mean Time to Recovery / Resolution — If there is a failure during a change, how long does it take you on average to recover?
Automating Our Measurement
We have data for most of these in our continuous integration and delivery tooling but it’s not necessarily easy to access or arranged in a clean time-series fashion. I carried out a manual proof of concept by checking the availability of data on the GoCD / Jira APIs and checking that I could put a measurement around each metric. With this foundation, I then worked on automating the data capture as a side project over the past couple of months which resulted in a simple architecture as follows.

Every hour a cronjob fires up a Python based Kubernetes pod that scrapes together updated information from GoCD and Jira then stores it as time-series information in Postgres. I’ve then built a dashboard in Grafana to present the information back to the team. Here is a little more detail on how we actually measure each of the 4 metrics.
Lead Time
We measure two different types of lead-time here.
First is the amount of time it takes to move an item of value from high level requirements through to a feature release (feature lead-time). You could argue that each user story should be small and deliver customer value independently but that’s not where we are 😉
Instead we are using a label in Jira to show the first and last story in an epic that delivers something valuable. In this way, we don’t force a specific process on the teams other than to use epics to encapsulate one or more features. This also deals quite elegantly with measuring lead time for features with overlapping timelines.
In our experience, it is difficult to design, build and release a new meaningful feature in a 1–2 sprint period (we run a 2 week sprint cycle). As a starting point our target for feature lead-time is <= 3 sprints / 42 days.

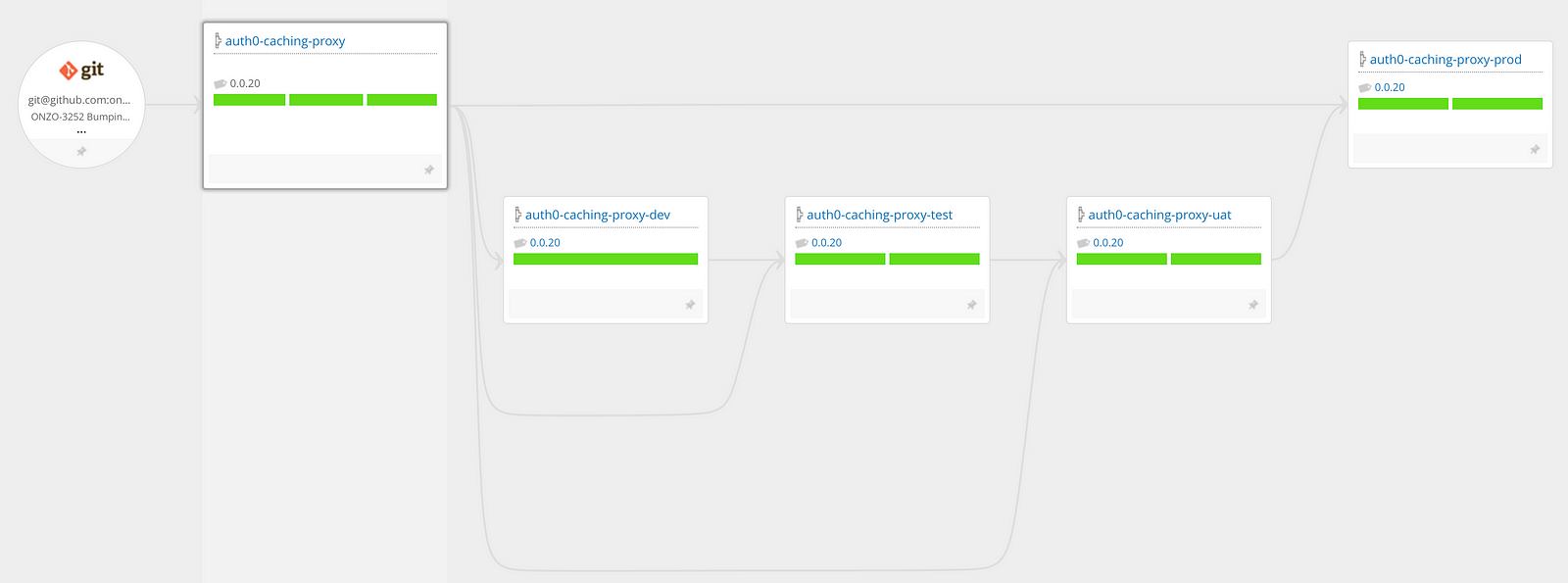
Second is the amount of time it takes from a merge into master to a component deployed in production (deployment lead-time). For this, our Python based cronjob is configured with a list of all production components. For each, it retrieves a history of deployments using the GoCD API. It then traverses backwards through the graph for the value stream keeping a record of semantic versions, pipelines, stages and jobs… Again, all as time-series data.
Our value stream involves a human element of QA review and Product Owner demo in the test environment. We therefore expect some builds to sit in est for a little while until the relevant person has capacity. Our baseline target for deployment lead-time is <= 5 days.
Deployment Frequency
A happy side effect of collecting such detailed data on GoCD pipeline, stage and job histories for deployment lead-time is that we have a good set of time series data ready for a slightly different query. We measure this as the number of successful production deployments in a time period
As with most teams our deployment frequency tends to ebb & flow. On a busy day we may perform 5–10 production deploys then carry out no deployments for the rest of the week. This is based on pull-requests getting merged and builds being signed-off. While establishing a baseline our target is an average of 1 production deployment per day over a 28 day period.
Note that we are not yet normalising for the number of engineers in the team on a given day.
Change Failure Rate
Our Python cronjob currently determines failures by looking for bugs with potential customer impact that are medium or higher priority by accessing the Jira API and replicating a normalised set of data across to Postgres. These bugs are mostly found by our internal teams with an occasional client raised one. The JQL for this is as follows;
project = ONZO AND type = bug AND (resolution not in ("cannot reproduce", duplicate, "won't do") OR resolution is EMPTY) AND labels = customer AND status not in (done, closed) ORDER BY priority DESC, status DESC
Change failure rate is then determined as bugs / production deployments in a given time period.Our baseline target is <= 10% (arrived at by measuring our starting point and setting a little tougher). Note that we are not yet including red production deployments or paged alerts in this number.
Mean Time To Resolution
Using the same Jira ticket information we measure from the ticket creation timestamp to the ticket resolution timestamp for MTTR.
In-line with customer facing SLAs our target for MTTR is <= 4 days
What Have We Observed?
Collecting all of the information above is grand, but if it’s not on a visible information radiator for the team we will never learn from it. Luckily we already had the perfect tool in place with Grafana as a dashboard for Prometheus (operational service monitoring). Once all the hard work of data collection had been automated it was around 30 minutes work to put the following dashboard together

I’ve had to manipulate some of the naming on the dashboard above but the numbers are all genuine. Without specifically focussing on improving any of the software delivery capabilities we have been running this experiment for about a month and have observed the following;
- Considering feature lead-time as a key indicator of performance is making us break features up and deliver value sooner (top left panel)
- We have one feature in-progress that will not hit the 42 day lead-time target. It is a key strategic improvement and we have accepted that a longer lead-time is better than releasing it half baked.
- The deployment cadence has increased and the lead-time for each deployment has decreased. This is mostly down to a new component called auth0-caching-proxy which has recently been developed. The feature release was decoupled from frequent deployments to reduce our risk resulting in a higher cadence. This worked really well and is a practice we intend to repeat.
- We have started converting generic support tickets into bugs more diligently and flagging them as potential customer impact so that we can track them
- Making bugs more visible has highlighted bottlenecks in our resolution process that has driven MTTR from ~18 days to ~3 days
Although we started from good foundations, note that have not put focussed effort into the capabilities yet. We have simply automated measurement, made it visible and started talking about the results.
What’s Next?
There are so many directions we can go in with this and I’m personally excited about the delivery practice visibility we are already getting from measurement. My wish-list around measurement is to;
- Gather data on how many developers were working on a given day from https://www.absence.io/. This will allow us to normalise deployment frequency to deployments per developer per day. Thankfully they have a nice API surfaced that will make this easy
- Start counting red production deployments as a change failure
- Start counting production alerts as a change failure
- Track the MTTR for both of the above
- Improve the Grafana dashboard to show both target achievement and trends over time
More significantly we now have a baseline and can focus on improving our capabilities in a measured way. This will be a key part of the objectives for our team as we get into the new financial year and should lead to some interesting improvements. Some example areas I expect we will focus on are;
- Speed of test automation — We have some build test cycles that take up to 20 or 30 minutes. We need to reduce these in order to push our release cadence higher
- Test data management — As a data analytics business it is paramount that we have easy access to test data and the abilities to manipulate it for testing in our delivery pipelines
- Shift left on security — We have good security practices. The further left we can shift them in our value stream the cheaper it becomes to maintain that high standard and the more deeply it becomes embedded in our culture
- Westrum organisational model — Our team is split across 3 sites in London, Edinburgh and Wrocław. This makes it even more important for us to foster the right environment with high communication bandwidth, high trust and bridging between our teams.
I’ll follow up with another blog post in 6–12 months sharing what we have learned. In the meantime, please let us know about your experiences in the comments below.