
Incidents — Trends from the Trenches
Incidents — Trends from the Trenches

Most publicized production incidents are war stories. Each involves drama with dead ends, twists and turns, and a victory at the end. Something innocuous happens, that then snowballs across several layers to take down some parts of a business. A big chunk of internal or external customers gets impacted. Several teams spend long hours on a conference call or in the war room to mitigate the customer impact.
You may recall well-publicized incidents like the AWS S3 outage in 2017 that impacted several AWS customers, including Apple iCloud, or the cyber attack on Dyn DNS that affected several American and European sites, or last year’s Amazon.com’s Prime Day outage.
Such incidents are rare, and yet they remain in our memories for years. In reality, most production environments encounter incidents almost every day. As you see below, the cumulative cost and customer impact of such incidents can be much larger than the infrequent dramatic ones.
During the fall of 2018, I set out to develop informed opinions on how to improve the availability of production systems at work. There is no dearth of architecture patterns, tools, techniques and processes available to improve availability. How do you determine which ones to focus on and when, and make continuous improvements? That was the question I was grappling with. More important, I also needed a way to challenge some of my own prior opinions.
Incident analysis
In order for this, I could think of no better way than to study incidents to spot patterns. During November and December of 2018, I spent several weeks to study several hundred production incidents. This sample set covered a very large set of customer-facing apps and services running on-prem and cloud, including some that are yet to be modernized, as well as the on-prem infrastructure. I meticulously went through each critical incident, read incident logs, and where available, reviewed postmortem reports and classified incidents based on a few categories of potential triggers.
A clarification on the terminology here. I’m using the term “trigger” and not “root cause” to classify incidents. This is to emphasize the fact that most production incidents have several root causes. A trigger may just have surfaced an incident.
This analysis was time-consuming and laborious. Yet, the insights I gathered were well worth the time I spent. In this article, I want to share my findings, offer some hypotheses to explain the findings, and what could be done to improve availability.
The chart below summarizes my findings. It shows the top 5 triggers behind these incidents, ordered by the cumulative customer impact.
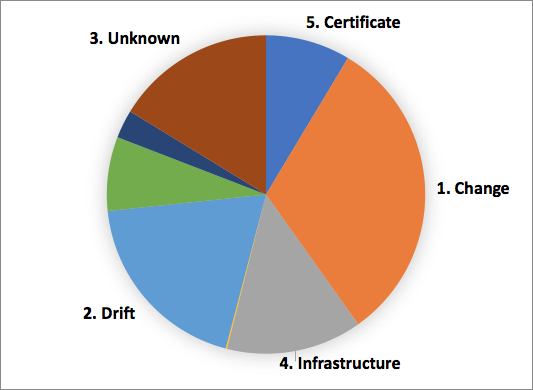
The size of each slice represents the customer impact as measured by certain metrics, and not the number of incidents.
Contrast this chart to the one below, which shows the incidents by number under each category.
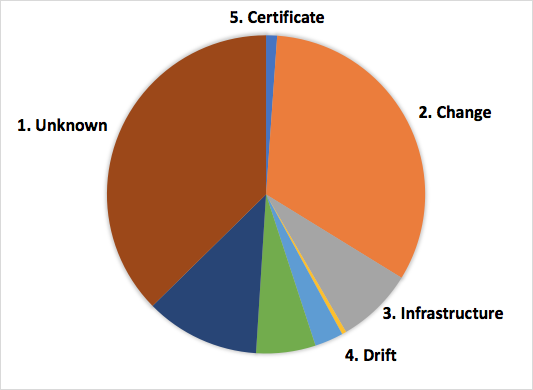
I omitted some categories in these charts due to those not being relevant for this article. A similar analysis of a different sample set of incidents might produce a different set of triggers, though I suspect that the above shows common trends across most large enterprises undergoing constant change. Few peers in the industry also conferred that they notice similar patterns.
Observation 1: Change is the most common trigger
About a third of the impact was triggered by changes. Of this, about 50% was due to software deployments. In my classification, a change could be any of the following:
- Automated CI/CD releases
- Semi-automated deployments legacy apps
- Manual changes
- Configuration changes, such as traffic routing, or ingress/egress filters
- Experiments (A/B tests)
As I showed in Taming the Rate of Change, given that the production environment at work undergoes a few thousand changes every working day, the change failure rate is still low. The impact, nonetheless, is significant.
This observation supports the anecdotal evidence for a low number of incidents during long weekends and holidays when production changes are low. Just last week, a colleague of mine quipped that production systems were mostly stable during the recent Seattle Snowmageddon 2019 because most people could not get to work. Some areas also lost power and Internet access during that time.
A couple of months before this analysis that produced the above pie charts, I analyzed a smaller sample of just over 100 critical incidents that covered a particular set of business functions. For each incident, I asked a simple question — was there a change that preceded the incident. I grouped all incidents with a “yes” into one bucket, and everything else into another bucket. The result is below.
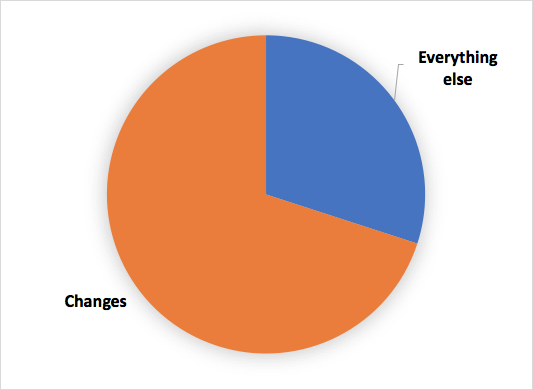
The result was surprising and extremely alarming. Over two-thirds of the sample of incidents was triggered by one or more changes. This finding led me to the latter analysis of the larger sample of incidents. Change is still at the top, by customer impact.
There is prior research to support this observation. An 2016 ACM paper titled Evolve or Die: High-Availability Design Principles Drawn from Google’s Network Infrastructure makes the following observation based on a detailed analysis of over 100 high-impact network failure events:
a large number of failures happen when a network management operation is in progress within the network.
Observation 2: Config drift accumulates over time and masks potential future incidents
The second trigger from the top is config drift, which contributed to about one-fifth of the impact.
For those not familiar with config drift, consider a cluster of nodes each of which is expected to maintain a certain configuration. The configuration may include the OS, OS level or application level dependencies, security groups and such access controls, config files etc.
The cluster could be a SQL database in an active-passive configuration, a Zookeeper cluster, or pair of network switches. In order for the cluster to stay healthy in case of failures of any one node, each is expected to be in a certain configuration. Now, say, due to someone manually making changes, or an automation defect, one of the nodes does not have the expected configuration. This is config drift.
It is fairly common for config drift to stay dormant for weeks or months and surface only when some other event happens. In one particular incident, one of the network switches configured in a pair drifted from its configuration. Months later, the other switch failed for some of the reason, and the drifted switch could not take over. This lead to network disruption. I’ve witnessed similar incidents in the past with other types of clusters, and have stories to tell.
Observation 3: We don’t always know why systems fail
The next biggest in my finding was a large number of incidents that recovered on their own after a while. Though this category was the third by customer impact (per the first pie chart in this article) on my list, it accounted for over 40% of the incidents (per the second pie chart) I examined.
To reiterate, for over 40% of incidents, there was an alert of customer impact, an incident was declared, relevant people got on the incident bridge, and while the investigation was ongoing, the impact mitigated by itself.
Unfortunately, such incidents don’t get the attention of postmortem analysis, and hence corrective actions.
Observation 4: Infrastructure issues are less frequent than commonly believed
Infrastructure related failures like data center power, disk or other hardware, WAN link etc. are less frequent than most people believe. The same is true for public cloud service or region failures. Such issues accounted for a smaller percentage of customer impact in my analysis.
In some of the incidents I reviewed, while initial investigations pointed to misbehaving infrastructure (such as a particular vendor’s appliance failing), further analysis revealed botched changes (see Observation 1) or config drift (see Observation 3).
Observation 5: Certificate related issues continue to be a headache
Finally, the fifth in my list is incidents related to certificate handling. There were just a handful of incidents in this category, and yet the impact was not insignificant. The issues related to forgetting to renew certificates in time or not coordinating the renewal across multiple systems. While these are easily fixable through automation or even processes, such errors continue to happen in complex production environments.
What is going on
Given the large sample size covering a diverse set of apps, services, and technologies, analysis like this provides an opportunity to better understand contemporary production environments at a high level. Below is my hypotheses of what might be contributing to these trends.
First, we trip on ourselves when making changes. The biggest risk to the availability of production systems is constant change. Due to the adoption of microservices, and investments into containers, CI/CD, and the cloud, our ability to make changes in production environments has been rapidly increasing. There is no turning back from this trend due to productivity gains. However, change safety is not always an inherent feature in the tools used to make changes.
As I argued in Taming the Rate of Change, these technology trends are contributing to the following:
- Hyperconnectedness: Enterprises are increasingly deriving value from connecting various services in numerous ways. In a sense, the value of the enterprise is slowly shifting from nodes (systems doing particular things) to edges (interconnectedness). This is increasing possibilities for both success and failure.
- Side effects: Amidst hundreds or thousands of services, anyone making a change to a particular microservice is unlikely to know all the consumers of that service across multiple layers.
- Hope driven releases: Production environments are often the only reliable environments to test a change. As most enterprises are decentralizing once-common release engineering discipline, pre-production environments are becoming stale, unreliable, and lightly monitored. Consequently testing in production is increasingly becoming vogue.
Second, the desire for speed may be stealing focus from automation. This analysis makes it clear that automation is rarely complete, with less frequently used parts of any workflow getting the least amount of attention.
Furthermore, as we move on from one generation of technology and architecture to the next one, we rarely leave the prior generation in the best possible shape.
Consequently, as systems age, less frequently used parts accumulate config drift. Unlike the other form of bugs, drift tends to remain dormant until some other event occurs before leading to a fault.
This trend is not limited to on-prem services. Apps and services deployed on the cloud are also subject to config drift. Teams adopting new technology usually start with automation to get going quickly, but not necessarily automate manageability tasks that come up in the future. This keeps the door open for drift to creep in.
Finally, the large number of incidents in the unknown category shows that our ability to comprehend the physics of hyperconnected systems is limited. Furthermore, as systems seem to recover on their own, we’re also losing the opportunity to learn from such incidents.
Potential ways to improve
This analysis certainly helped me refine my opinions on areas of investments. I want to highlight a few techniques to help deal with the trends I noticed.
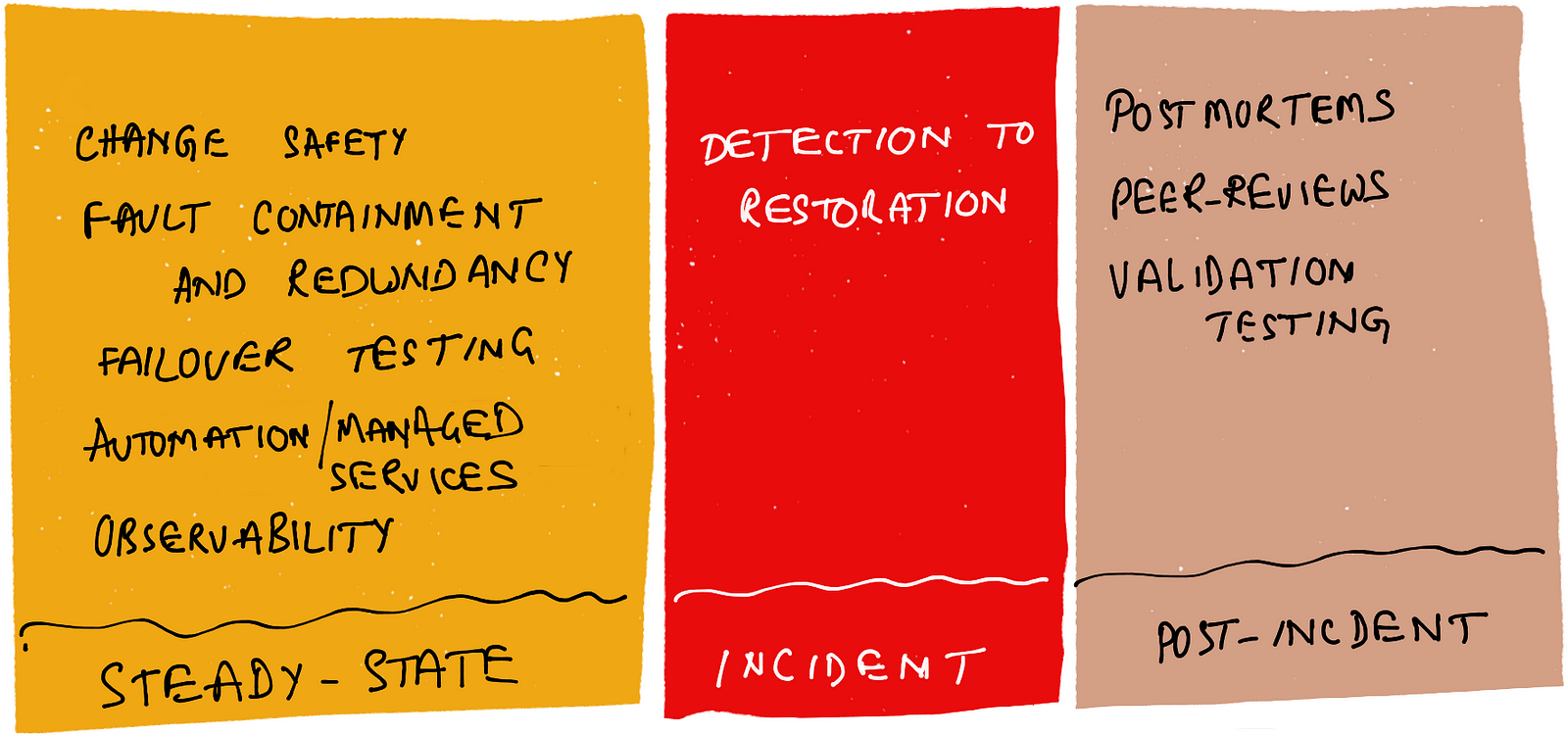
First, the most important take away from this analysis is improving change safety. Progressive deployments (i.e., introducing the change bit by bit), feature flags, blue-green deployments, predictable rollbacks, and shadow testing are some of the ways to improve change safety. Anyone interested in increasing deployment frequency must also invest in such safety strategies.
The second area of investment is fault containment and redundancy. Some of the complex incidents take time to restore, and traffic shifting to a redundant copy (active or passive) may provide a faster and reliable alternative to in-place fire-fighting. See my article on Fault Domains and the Vegas Rule for a description of how redundant fault domains can help reduce time to restore. Another excellent article to read on this topic is Werner Vogels’ Looking back at 10 years of compartmentalization at AWS which describes how AWS uses “compartmentalization” for horizontal scalability as well as to contain faults to smaller domains.
However, maintaining redundancy is non-trivial. Apart from designing for redundancy, periodic traffic-shifting practice drills are essential for maintaining fault domain integrity and readiness to shift traffic.
The third area of investment is to either commit fully to automate systems or use a cloud-managed service to take care of most of the automation. I always recommend the latter due to increased time to market and lower operational overhead. Though this does not fully eliminate the possibility of config drift, it can at least help reduce the number of moving parts you’ve to automate yourself.
Next in the list of areas of investment is observability, in particular, tracing, to improve steady-state understanding of today’s hyperconnected production environments. Traces and service graphs help improve a team’s understanding of how their services are used and how they are behaving during the steady-state.
The fifth and the second most important area after change safety is investing to increase the time spent after incidents through post-incident rituals. Across the industry, most teams treat incidents as distractions and are eager to get back to regularly scheduled work as soon as systems are restored. This trend needs to change as incidents teach us about non-linear behaviors of complex hyperconnected systems. At work, we’re experimenting incorporation of a few post-incident rituals like peer-reviews of postmortem reports, and in some cases, subjecting the system in production to the similar triggers after fixes have been made.