
Evolving search recommendations on Pinterest – Pinterest Engineering – Medium
Maesen Churchill | Software engineer, search
Pinterest is all about helping people discover ideas to try in real life, whether it’s a recipe to cook, a product to buy or a trip to take. Search is a key part of discovery, and we handle billions of queries every month. On Pinterest we find that people want to explore possibilities much more often than just getting a single result. In fact, nearly 75 percent of queries are just 1–3 words, and people view an average of 60 Pins per-query. This kind of open mindset is what makes Pinterest Search so different from traditional search engines.
Over the last year, we introduced recommended queries to help Pinners explore related ideas throughout their search. We make recommendations based on boards a Pinner creates and the Pins they save. This post will explore the evolution of search recommendations, specifically the query-based search suggestions in Pinterest Search.

Recommended query candidate generation
Term-Query graph
The Term-Query (TQ) graph was initially our only data source for recommended searches. The TQ graph is a graph of terms and queries built using the following rules:
- Terms (unigrams) are connected to queries in which they appear, and TQ edges are weighted by the reciprocal of the number of queries that term shows up in.
- Query-query edges are weighted according to how “related” the queries are. Low-weighted query edges are culled.
We trained a logistic regression model to determine query relatedness. Training set labels were generated through Sofia, our human evaluation platform.

Once the TQ graph was built, we used the following procedure to generate recommended searches for a given query:
- Break the query up into terms,
- Start at each of those term’s nodes in the graph, and
- Do a random walk (with restart) from each term in the original query, moving from one query node to another with probability proportional to the query-query edge weight. Intuitively, we want to find the queries “central” to the term nodes.
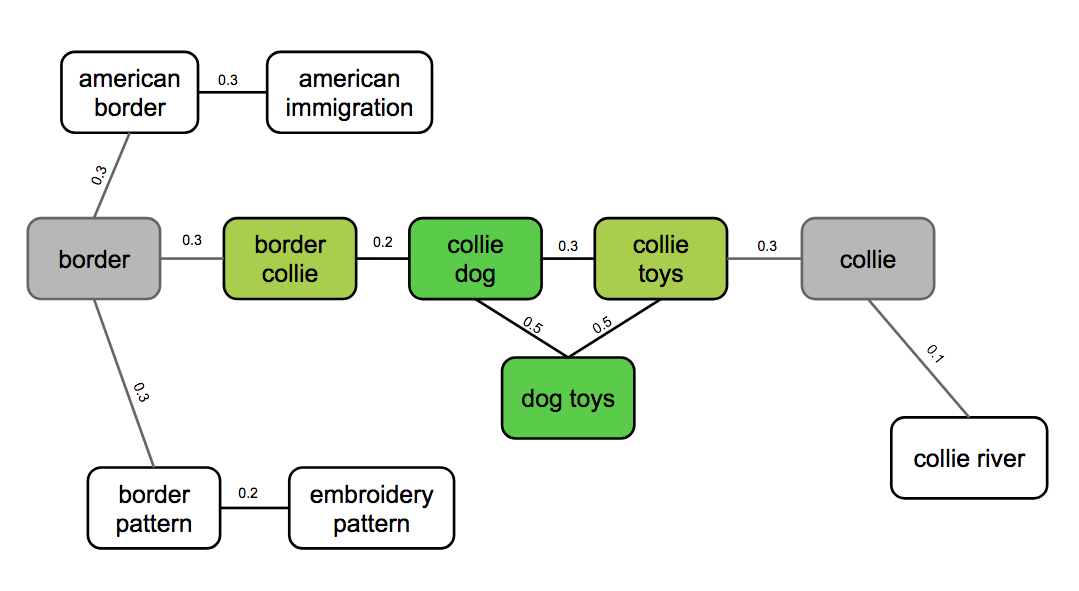
For each starting term, we arrive at a stationary distribution describing the probabilities of arriving at various queries from that term. We then find the Hadamard product (“dot product”) of each stationary distribution. If a query appears in one term’s stationary distribution but not another, we have logic to add it to the stationary distribution with a low probability. In this way, we don’t require queries appear in all terms’ stationary distributions to be recommended. However, we do penalize such terms, because if not all terms in the original query are used to generate recommendations, the recommendation quality can break down. In other words, we recommend the queries most frequently visited in the random walks, provided there’s enough overlap in the queries visited from the various start nodes.
The TQ graph gives us excellent recommendation coverage, but it doesn’t use a lot of information about how Pinners use search on Pinterest.
Pixie query-Pin graph
Our next candidate source used is Pixie, our graph-based recommendation platform, to generate search suggestions based on historical engagement. We generated a bipartite graph, this time from queries to Pins. We connect nodes if a user engaged with a given Pin after searching a given query. To get search recommendations for a query, we do a random walk of the graph starting at the corresponding query node and then recommend the most commonly visited query nodes.
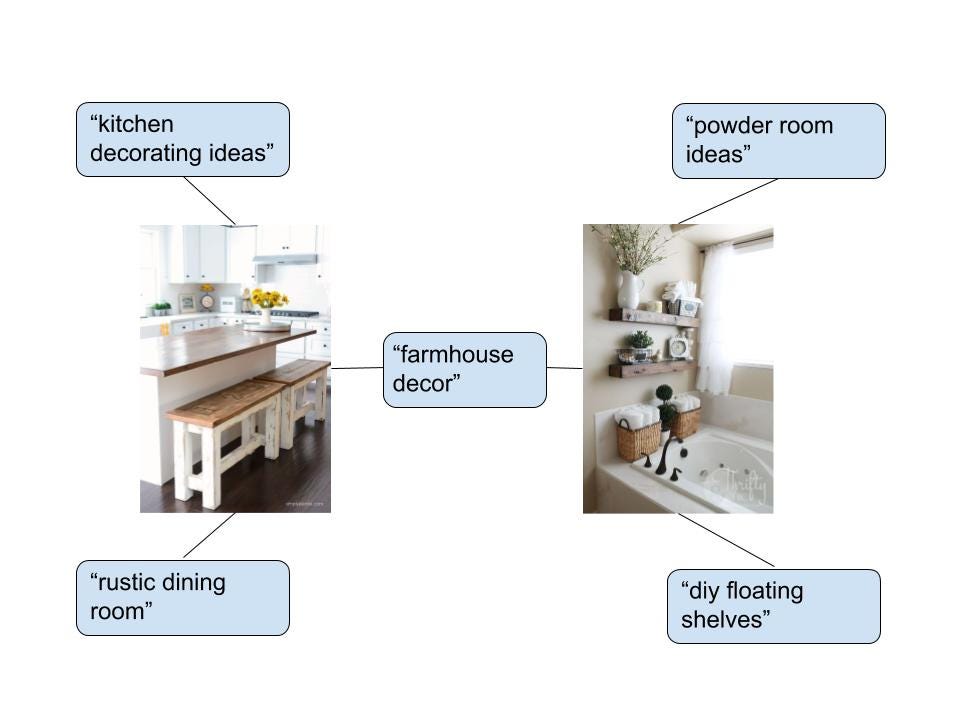
Since it takes into account Pins people save, search for and more, the query-Pin graph captures conceptual similarity in a way the TQ graph doesn’t. When you break down a query into terms and do a random walk on the TQ graph, you lose semantic information. For example, the query “old fashioned” yielded suggestions such as “fall fashion for work” and “mens fashion casual” from the TQ graph. The term “fashioned” gets normalized to “fashion,” and the stationary distribution of queries for this term are irrelevant to the cocktail. However, the query-Pin graph will provide more relevant suggestions:
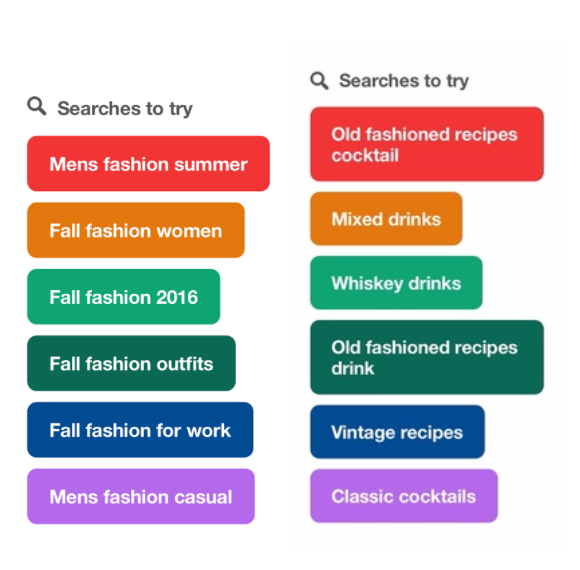
When available we prioritize Pixie candidates over everything else. However, we only have search suggestions if the query has sufficient historical engagement. The TQ graph ensures we have suggestions for less common and even some never-before-seen queries.
Recommended query serving
Query-based search recommendations were initially served as part of the search request. Logic for candidate generation, deduplication, sensitive term filtering and candidate ranking was distributed between our query understanding backend (Anticlimax) and search backend (Asterix). This serving system had two major drawbacks:
- Preparing recommended queries contributed latency to carrying out the search request, even though most of this work could be parallelized with Pin result retrieval and ranking.
- Logic for candidate deduplication, filtering and ranking should be shared for all search recommendation stories: search result page recommendations, Pin closeup recommendations, recommendations on boards, etc. This isn’t possible when the logic is locked in the body of the search request.
Given these drawbacks, we removed the search recommendation logic from the search backend and created a new service for query recommendation called Dogmatix.
Each request to Dogmatix provides query(ies), Pin ID(s), board ID(s) and/or user ID(s), as well as information about the user making the request. Each request has three stages:
- Candidate generation: This stage is different for each type of request (query-based, Pin-based, etc.). For query-based requests, we fetch the TQ and Pixie candidates described above.
- Query understanding: At this stage, we call the query understanding backend (Anticlimax) to get information about the candidates. We tag the candidates with information like detected language, popularity and sensitive query detection information.
- Scoring/ranking: At this stage, we filter sensitive candidates, deduplicate the results and rank the candidates.
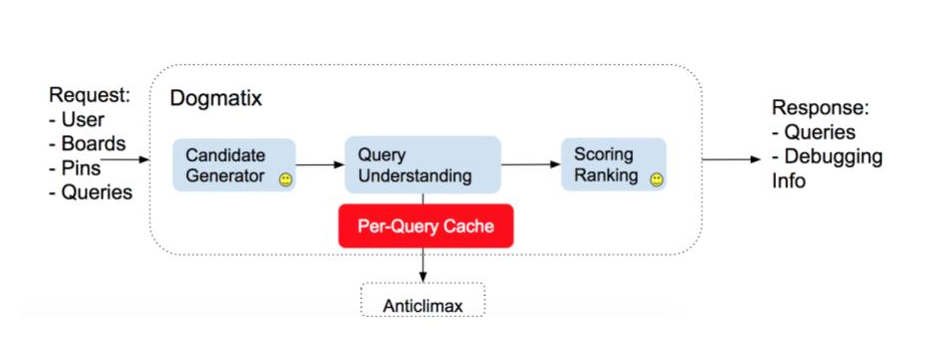
Dogmatix is called from the API layer. In the case of query-based recommendations on the search result page, we make the Dogmatix call in parallel with the Asterix (search backend) call.
Future work
Our future work will focus on increasing the coverage for recommended queries so that we’re able to launch this feature to Pinners outside the U.S. We’re currently working on a query embedding model to use as a new data source. Eventually we’d like the ability to generate an embedding for an arbitrary (perhaps never-before-seen) query, and find queries with similar embeddings.
We plan to improve suggestions by considering more than just the data presented in the original query. For example, if the searcher refines their food query using a “vegetarian” filter, or if the searcher is specifically clicking minimalist design Pins on a home decor query, we’ll be able to tailor our suggestions with this additional context to make it more specific.
We also plan to experiment with the positioning of recommended searches. Right now, search recommendations are placed in a fixed position in the grid. We’re hoping to dynamically move suggestions up or down based on our confidence in the recommendation.
We’re constantly trying to improve our system to continue giving Pinners great recommendations that keep them inspired and coming back to Pinterest to find their next idea. If you like working on search and recommendations problems, join our team!
Thank you to Cindy Zhang, Jack Hsu, Jerry Liu, Juliana Cook, Laksh Bhasin, Leo Liu, Matt Fong, Mustafa Motiwala, Valerie Hajdik, Ying Huang, and Yan Sun