
Scalable and reliable data ingestion at Pinterest – Pinterest Engineering – Medium
Yu Yang | Pinterest engineer, Data
At Pinterest, we use data to gain insights to make decisions for everything, and ultimately improve the whole experience for Pinners. Every day we log over 100 terabytes of data. In order to use data effectively, we first have to reliably ingest it and prepare it for downstream usage. In this post, we’ll cover the evolution of our data ingestion pipelines and present our current data ingestion infrastructure. Looking ahead, we’ll have a series of follow-up posts to describe each component in greater detail.
Data ingestion overview
Data ingestion is all about collecting data from various sources and moving it to persistent storage. The data typically spreads across tens of thousands hosts in various formats, and so doing this in a reliable, efficient and scalable way is a challenging and fun task.
Data ingestion generally has the following requirements:
- Reliability: data collection and transportation should be reliable with minimum data loss
- Performant: the pipelines should have high throughput and low latency
- Efficient: there should be minimum computation and storage resource usage
- Flexibility: it should support various sources and data formats
- Autonomous: the system should run with minimal operational overhead
At Pinterest, there are two primary categories of data sets: online service logs and database dumps. Service logs are continuous log streams generated by services across thousands of hosts. The pipeline for collecting service logs is usually composed of three stages: log collection, log transportation and log persistence. Database dumps are logical database backups and are generated hourly or daily. Database ingestion often includes database dump generation and post processing.
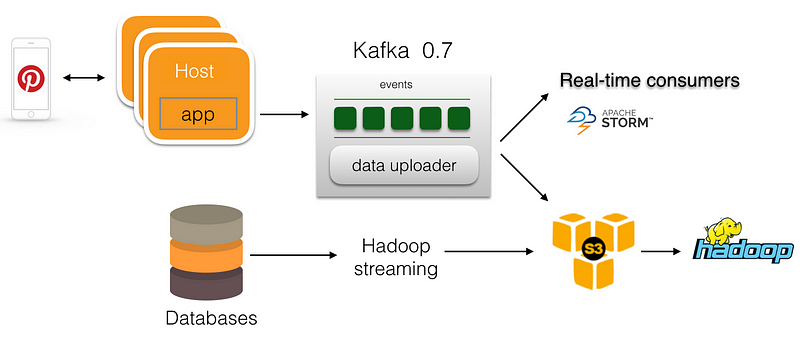
Figure 1 shows the ingestion pipelines in 2014. At that time, we used Kafka as the central message transporter on the online service side. The app servers wrote log messages directly to Kafka. A data uploader on each Kafka broker uploaded Kafka log files to S3. On the database dump side, we had a customized Hadoop streaming job to pull data from database and write the results to S3. However, there were a few issues with this setting:
- With directly writing from appserver to Kafka, if Kafka brokers had an outage, messages needed to be buffered on the server side in memory. As the buffer size is limited, an extended Kafka outage would lead to data loss.
- There was no replication in Kafka 0.7. Kafka broker failure would cause data loss.
- To minimize the impact of online services, we can only take database dumps from slave nodes. We need to keep track of master-slave mapping, and frequent database dump failover can increase the failure of these jobs.
- Operation overhead was high.
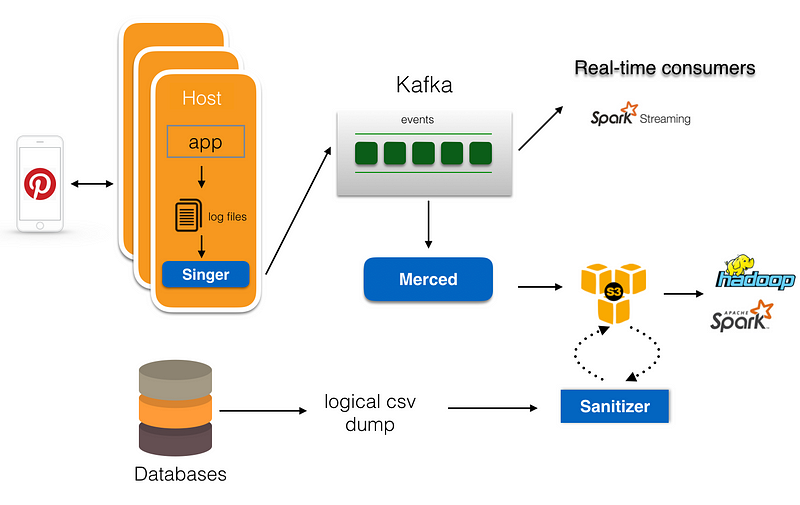
To address these issues, we enhanced various stages of data ingestion. Figure 2 shows the updated architecture where we made the following changes to data ingestion pipelines:
- For online service logging, instead of directly writing to Kafka, the services write log messages to local disk.
- We built a highly performant logging agent called Singer that uploads log messages from hosts to Kafka. Singer supports multiple log formats and guarantees at-least-once delivery for log messages.
- We evolved Secor and built a data persisting service called Merced to move data from Kafka to S3. Merced uses low-level consumer to read messages from Kafka, and employs a master-worker approach to distribute data persisting workloads among workers. Merced guarantees exactly-once message persistence from Kafka to S3.
- We added a sanitization stage to the pipeline for data sanitization tasks (e.g. schema enforcement checking, deduplication, data policy enforcement and more).
- On the database ingestion side, instead of using a Hadoop stream to pull data from the database, the databases directly store logical dump to S3, and use the sanitization framework to generate the datasets needed for downstream processing.
- We built end-to-end auditing and data completeness checking, and improved visibility in each stage of the pipeline to reduce operation overhead.
With this setting, we’ve been able to handle >150 billion messages per day and >50TB of logical database dump. With a growing user base of 175 million people every month, and an ever expanding graph of 100 billion Pins, we face new challenges every day:
- Logical CSV dump generation often gets delayed due to database masters failover. This prevents downstream from getting fresh data on time. We need to ingest database data in an incremental way to improve reliability and performance of database ingestion.
- Data pipeline creation and on-boarding need to be further simplified.
- Kafka operation becomes a challenge when we scale up Kafka clusters.
- More events may arrive late for various reasons, we need to handle late-arrived events consistently.
We continue to evolve our data ingestion pipelines, and will share more in follow up posts. If these are the kinds of problems that excite you, join us.
Acknowledgements: Many engineers at Pinterest helped to build and improve the data ingestion infrastructure at Pinterest, including Henry Cai, Roger Wang, Indy Prentice, Shawn Nguyen, Yi Yin, Dan Frankowski, Rob Wultsch, Ernie Souhrada, Mao Ye, Chunyan Wang, Dmitry Chechik and many others.