
Speed up your site with a little machine learning – Hacker Noon
But recently I’ve been wondering if my definition of web performance is too narrow. From a user’s perspective, all that jazz is a tiny piece of the performance pie.
So I opened up a site I am quite familiar with and went through all the things a user might do, timing each one. (We need a user journey timeline tool.)
Before long I found a step I thought could be improved.
The rest of this article focuses on this one particular step on one particular site. But I’d like to think the solution (which is obviously going to be machine learning) could be applied similarly to many different scenarios in many different sites.
The problem, distilled
The example site is one where a user can sell their trash, so that another person can buy some treasure.
When a user posts a new item for sale on this site, they select which category their item belongs in, then select the advertising package they want, fill out the details of their item, preview the ad, then post the ad.
That first step — selecting a category — rubs me the wrong way.
Firstly, there’s 674 categories and I don’t really know which one my crappy kayak ‘belongs’ in. (Steve Krug said it well: Don’t make me think)
Secondly, even when it is clear which category/sub-category/sub-sub-category my item belongs in, the process still takes about 12 seconds.
If I told you I could reduce your page load time by 12 seconds, you’d rightfully go mental. Well, why not go just as mental about saving 12 seconds somewhere else, hmmm?
As Julius Caesar famously said: “12 seconds in 12 seconds, man.”
And so, quite blissful in my ignorance, I reckoned that if I fed the title, description, and price of an item into a properly-trained machine learning model, it should be able to work out what category that item belongs in.
So rather than a user spend all that time selecting a category, they could spend 12 extra seconds looking at DIY bunk beds on reddit.
Machine Learning — and why you should stop running away and get back here
When this began, I knew absolutely nothing about machine learning, other than it could play video games, and outperform the world’s best go-go dancer at chess.
So I set out to learn everything there was to know. The following steps took less than an hour:
- Googled “Machine Learning”
- Clicked a lot
- Discovered Amazon Machine Learning
- Realised I didn’t need to know a thing about machine learning
- Relaxed
(Note: since I never got around to actually learning machine learning, I’m probably misusing the terminology all over the place.)
The process, in a nutshell
Amazon has nailed it with their ML documentation. If your interest is piqued by this post, put aside ~5 hours and go read it, I won’t attempt to summarise it all here.
After reading the docs, I had formulated a plan, and it was this:
- Get some data in a CSV file. Each row should be an item (e.g. my kayak), columns should be title, description, price, and category
- Upload that into an AWS S3 bucket
- ‘Train’ the machine with that data (this is all done via a UI— a wizard with inline help, no less). The little cloud robot should then know how to predict the category based on a title, description and price.
- Add some code to my front end that takes the title/description/price that the user has entered, send it to the prediction endpoint (this was automagically created for me by Amazon), and show the predicted category on the screen.
The mock site
I’ve put together a gorgeous form that simulates the key aspects of this process.
Here’s the exciting results to keep you interested during the boring bits coming up. You’ll just have to believe me that the suggested category really was a prediction from a machine learning model.
Let’s try selling a fridge:

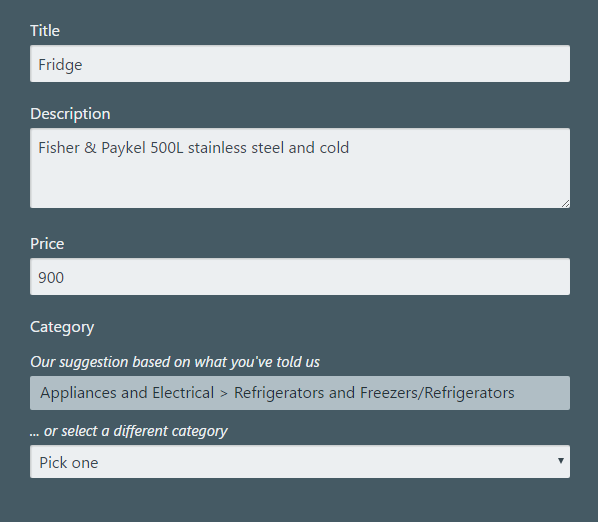
What about a fish house:


The little cloud robot knows what an aquarium is!
I must admit I did a little happy dance when I saw this. I mean, it’s pretty great, right?
(If you’re curious how I made the form, I used React and Redux and jQuery and MobX and RxJS and Bluebird and Bootstrap and Sass and Compass and NodeJS and Express and Lodash. And WebPack for bundling. The finished thing is barely over 1 MB — #perfwin.)
OK, on to the less flashy parts.
Because I’m just messing around here, I needed to get some data from somewhere. I wanted about 10,000 items over a few dozen categories. I found a local trading site, had a look at their URLs and DOM, then wrote a little scraper that outputted the results to CSV. This actually took about four hours, a full half of the total time it took to get all this working.
When I had my CSV, I uploaded it to S3, and went through the wizard to set up and train a machine learning model. The total CPU time for training was 3 minutes.
The interface has a neato real-time prediction area, so I can test that if I pass it certain parameters, it’s going to give me back what I want.

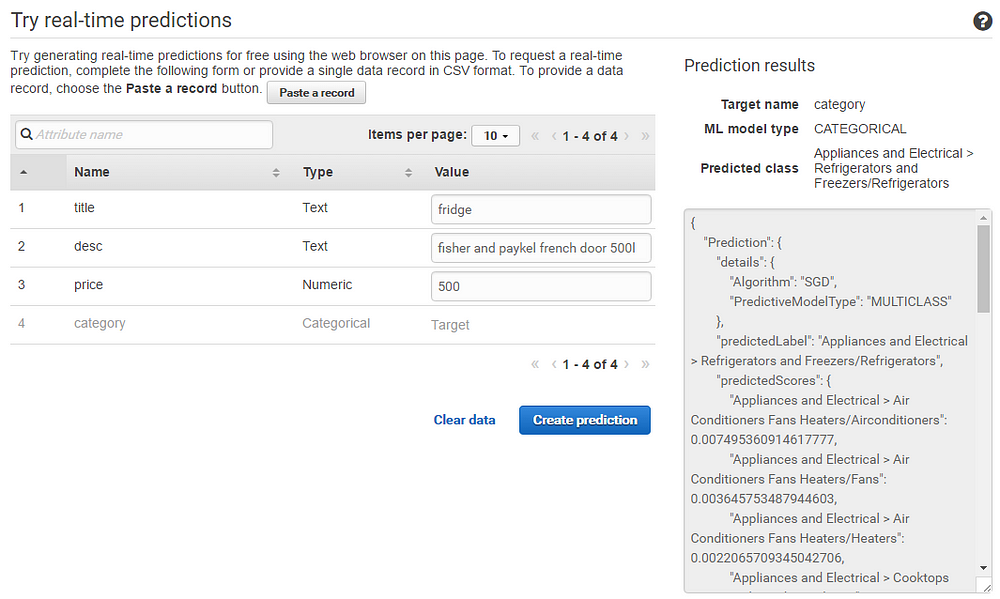
OK so it works. Tops.
Now, I don’t want to hit the Amazon API directly from the browser, because I don’t want it to be public. So instead, I’ll hit the API from my Node server.
The back end code
The general approach is pretty straightforward. I pass the API my model ID and some data, and it responds with a prediction.
I almost gave up at this point because I find it very hard to concentrate when there are properties starting with capital letters on my screen. But I soldiered on.
The record, sorry, I mean Record, is a JSON object where the properties are what I trained the model on (title, description, and price).
I don’t want to be that guy that provides not quite enough code to be helpful, so here’s my entire server.js file that exposes a /predict endpoint:
And the contents of aws-credentials.json:
(Obviously my /private directory is in .gitignore so won’t be checked in.)
Alrighty, that’s the back end sorted.
The front end code
The code behind the form is fairly straightforward. It does this:
- Listens for the blur event on the appropriate fields.
- Gets the values from the form elements.
POSTs them to the/predictendpoint I created in the Node code above.- Puts the resulting prediction in the category field and shows that whole section.
forEach on a NodeList?That’s it. That’s 100% of the code required to have a machine learning cloud robot take input from a user and predict the category that their item belongs in.
Shut up and take my money
Hold on to your hats compadres, all this magic doesn’t come for free…
The model I used for the above (trained on a measly 10,000 rows/4 columns) is 6.3 MB. While I have my endpoint waiting to receive requests, I’ll incur a charge for 6.3MB worth of memory. The cost is $0.0001/hour. Or about eight bucks a year. I spend more than that on mittens.
There is also a charge of $0.0001 for each prediction. So, you know, don’t go predicting things willy nilly.
Of course, it’s not just Amazon offering the goods, but I didn’t get as far a pricing for the other two big players.
Google has TensorFlow, but they lost me at the first bullet point in the getting started guide.
Microsoft has a Machine Learning offering too, but I’m still mad at them for IE6. (Or maybe, coming soon, an Amazon vs Microsoft showdown post.)
A sort of summary
Perhaps I’m just easily amazed (I still remember when I realised that ‘news’ is the plural of ‘new’) but I think this is all pretty damn amazing. It allows the average person like you (and to a lesser extent, me) to dabble in machine learning and potentially make some great improvements for the users out there.
Where to next?
The above example is certainly contrived, and I’ll admit, I left out the screenshot where it thought a toaster was a horse.
I could list off all the problems I can foresee, but surely it’s more fun if you go and discover them for yourself.
So go, play, and if you have some success, I’d be delighted to hear about it in the comments.