
Ship Small Diffs
I regret to inform you that your code has to be deployed
Building a web application is a young and poorly-understood activity. Toolchains for building code in general are widely available, relatively older, and they also happen to be closest at hand when you’re getting started. The tendency, then, is to pick some command line tools and work forwards from their affordances.
Git provides methods for coping with every merge problem conceivable. It also gives us support for arbitrarily complicated branching and tagging schemes. Many people reasonably conclude that it makes sense to use those features all the time.

This is a mistake. You should start from practices that work operationally, and follow the path backwards to what is done in development. Even allowing for discardable MVP’s, ultimately in a working business most of the cost of software is in operating it, not building it.
I’ll make the case for one practice that works very well operationally: deploying small units of code to production on a regular basis. I think that your deploys should be measured in dozens of lines of code rather than hundreds. You’ll find that taking this as a fixed point requires only relatively simple uses of revision control.
Ship small diffs, and stand a snowball’s chance of inspecting them for correctness.
Your last chance to avoid broken code in production is just before you push it, and to that end many teams think it’s a good idea to have standard-ish code reviews. This isn’t wrong, but return on effort diminishes.
Submitting hundreds of lines of code for review is a large commitment. It encourages sunk cost thinking and entrenchment. Reviews for large diffs are closed with a single “lgtm,” or miss big-picture problems for the weeds. Even the strongest cultures have reviews that devolve into Maoist struggle sessions about whitespace.

Looking at a dozen lines for mistakes is the sort of activity that is reasonably effective without being a burden. This will not prevent all problems, or even fail to create any new ones. But as a process it is a mindful balance between the possible and the practical.
Ship small diffs, because code isn’t correct until it’s running production.
The senior developer’s conditioned emotional response to a large deploy diff is abject terror. This is an instinctive understanding of a simple relationship.

Every line of code has some probability of having an undetected flaw that will be seen in production. Process can affect that probability, but it cannot make it zero. Large diffs contain many lines, and therefore have a high probability of breaking when given real data and real traffic.
In online systems, you have to ship code to prove that it works.
Ship small diffs, because the last thing you changed is probably setting those fires.
We cannot prevent all production problems. They will happen. And when they do, we’re better off when we’ve been pushing small changesets.
Many serious production bugs will make themselves evident as soon as they’re pushed out. If a new database query on your biggest page is missing an index, you will probably be alerted quickly. When this happens, it is reasonable to assume that the last deploy contains the flaw.
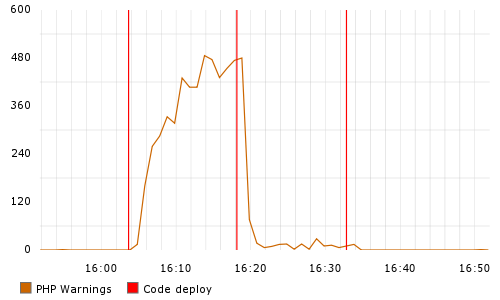
At other times, you’ll want to debug a small but persistent problem that’s been going on for a while. The key pieces of information useful to solving such a mystery are when the problem first appeared, and what was changed around that time.
In both of these scenarios, the debugger is presented with a diff. Finding the problem in the diff is similar to code review, but worse. It’s a code review performed under duress. So the time to recover from problems in production will tend to be proportional to the size of the diffs that you’re releasing.
Taking Small Diffs Seriously
Human frailty limits the efficacy of code review for prophylactic purposes. Problems in releases are inevitable, and scale with the amount of code released. The time to debug problems is a function of (among other things) the volume of stuff to debug.
This isn’t a complicated list of precepts. But taking them to heart leads you to some interesting conclusions.
- Branches have inertia, and this is bad. I tell people that it’s fine with me if working in a branch helps them, as long as I’m not ever able to tell for sure that they’re doing it. It’s easier to double down on a branch than it is to merge and deploy, and developers fall into this tiger trap all the time.
- Lightweight manipulation of source code is fine. PR’s of GitHub branches are great. But
git diff | gist -optdiffalso works reasonably if we are talking about a dozen lines of code. - You don’t need elaborate Git release rituals. Ceremony such as tagging releases gets to feel like a waste of time once you are releasing many times per day.
- Your real problem is releasing frequently. Limiting the amount of code you push is going to block progress, unless you can simultaneously increase the rate of pushing code. This is not as easy as it sounds, and it will shift the focus of your developer tooling budget in the direction of software built with this goal in mind.
That is not an exhaustive list. Starting from operations and working backwards has lead us to critically examine what we do in development, and this is a good thing.
This post is about the design principles that inform Skyliner. Skyliner is a continuous delivery launch platform for AWS, and is free for personal use. Sign up today!
For a limited time, we’ll help you switch your Heroku app to Skyliner for free.